Introduction
This document describes the troubleshooting steps to handle memory errors on UCS Servers.
Prerequisites
Requirements
Cisco recommends that you have knowledge of these topics.
- Basic understanding of UCS.
- Basic understanding of Memory Architecture.
Components Used
The information in this document is based on these software and hardware versions:
- UCS Family Servers M5, M6, M7 and higher.
- UCS Manager
- Cisco Integrated Management Controller (CIMC)
- Cisco Intersight Managed Mode (IMM)
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, ensure that you understand the potential impact of any command.
Background Information
Memory Errors
Memory errors are encountered when an attempt is made to read a memory location. The value read from the memory does not match the value that is supposed to be there. These errors are classified into two types:
1. Soft errors
Soft errors are transient and do not continue to be repeated. These are temporary and can often be corrected by retrying the read or rewriting the memory location.
2. Hard Errors
Permanent physical defects cause these. Rewriting the memory location and retrying the read access does not eliminate a hard error. As a result, this memory error is uncorrectable, and the memory needs to be replaced as the error continues to repeat.
Correctable Errors
If errors are detected and corrected, they are considered correctable. This can be accomplished by retrying the read or by calculating the correct memory contents using Error Correction Code (ECC) data and writing the proper data back into memory. After an error is detected and corrected, the Cisco Integrated Management Controller (IMC) logs the event in the System Event Log.
Typically, correctable errors are the result of soft errors. If correctable errors persist within the same memory location over an extended period, it could indicate a potential hard error.
Adaptive Double Device Data Correction (ADDDC)
ADDDC Sparing can correct two successive DRAM failures if they reside in the same region. ADDDC dynamically moves data from failing bits to spare memory, preventing correctable errors from becoming uncorrectable. A threshold of correctable ECC errors is required to trigger the mechanism.
ADDDC helps in some scenarios where correctable ECC errors precede Uncorrectable ECC errors.
Post Package Repair (PPR)
Post Package Repair (PPR) can permanently repair failing memory regions within a DIMM by leveraging redundant DRAM rows. This permanent in-field repair allows for rapid recovery from hard errors without needing to replace the DIMM. To perform a repair, the system must experience an ADDDC event and go through at least one reboot cycle. This repair activity does not affect performance or the total memory available to the OS.
PPR and ADDDC are enabled by default, however, can be configurable. PPR requires ADDDC Sparing RAS mode to also be enabled. If the RAS setting is other than ADDDC Sparing or Platform Default, PPR is not operational. The only supported PPR mode is Hard PPR, which means repairs are permanent.
Partial Cache Line Sparing (PCLS)
There is an error-prevention mechanism in the memory controller. It works by identifying faulty small portions of data in memory. These faulty locations are recorded in a special directory, along with backup data that can replace them. When the memory is accessed, if there is an error in those faulty spots, the controller uses the backup data from the directory to ensure everything runs smoothly.
Note: The features are available depending on the CPU architecture and the firmware version running on the server. Ensure you are in the last recommended version to handle the memory errors better.
Troubleshoot RAS Faults
UCS Manager
Generally, you see these faults in UCS Manager as an RAS event.
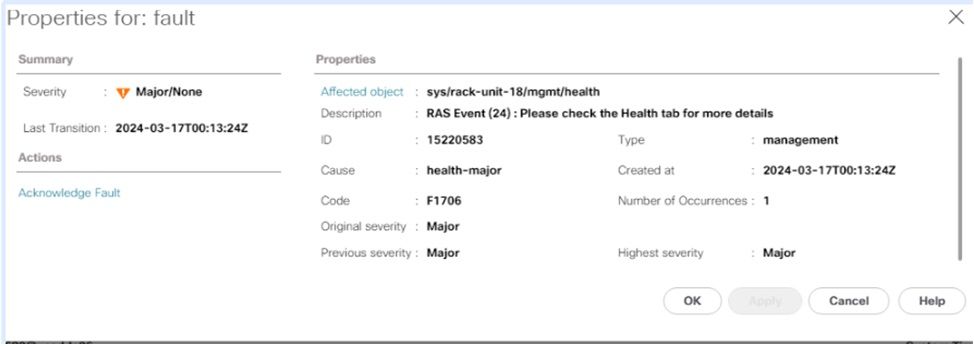
In the health summary, you can find more information about the error, whether PCLS or PPR was triggered.
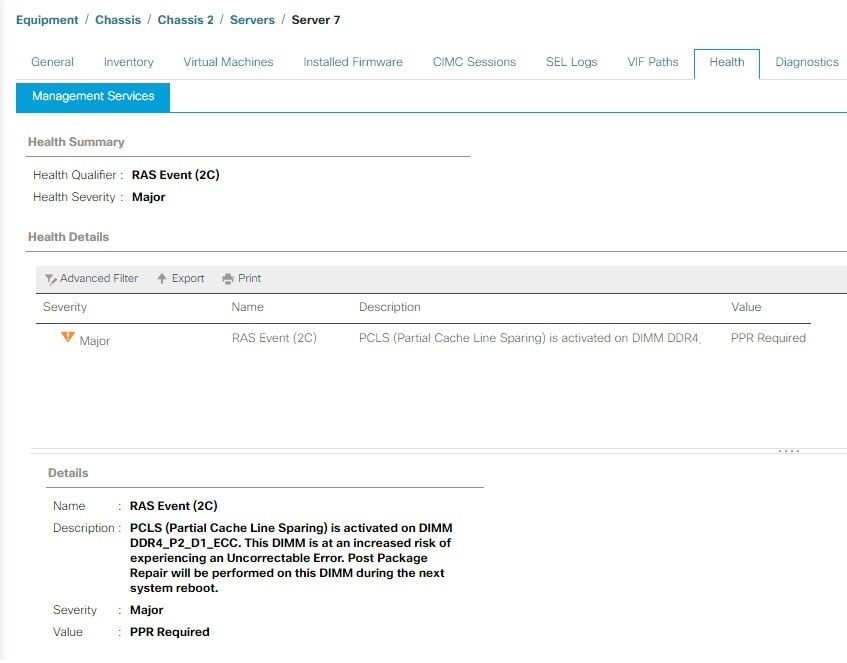
PCLS example
On M6 servers and newer, you have the option to enable Patrial cache line sparing (PCLS) as a BIOS option, which is an error-prevention mechanism. The server must be rebooted as soon as possible, so PPR can kick in and repair the DIMM. Once the server is rebooted, monitor for additional UCS Manager faults for the same DIMM.
As the alert mentions, it is recommended to reboot the server at the earliest convenience, since there is an associated risk of experiencing an Uncorrectable Error, and consequently an unexpected server downtime.
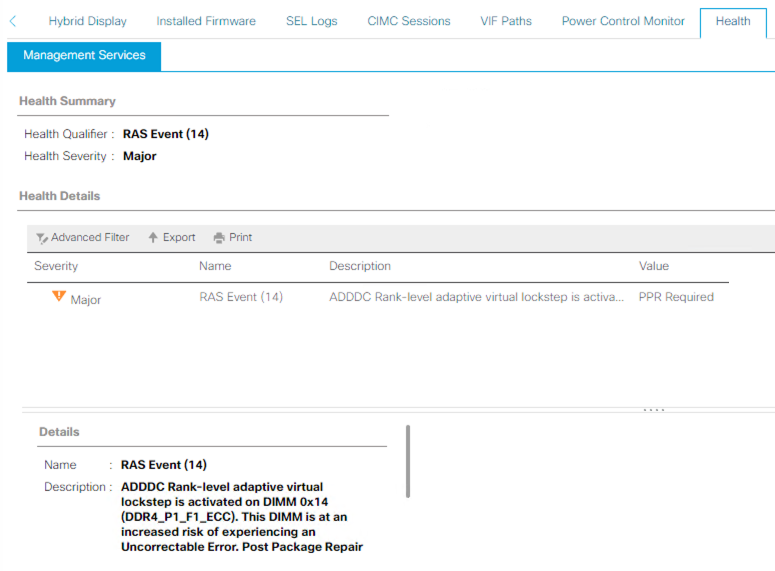
PPR example
The server has ADDDC and PPR enabled, and a RAS event occurred. The fault suggests rebooting for PPR to repair the DIMM. The server needs to be rebooted as soon as possible for PPR to kick in and repair the DIMM.
Once the server is rebooted, monitor for additional UCS Manager faults for the same DIMM.
As the alert mentions, it is recommended to reboot the server at the earliest convenience, since there is an associated risk of experiencing an Uncorrectable Error, and consequently an unexpected server downtime.
Intersight Managed Mode
The Server has ADDDC enabled, and a BANK VLS event occurred, creating the fault you see. In this scenario, the next step is to perform a server reboot as soon as possible to allow PPR to be executed.

Cisco Integrated Management Controller (CIMC)
The fault appears as shown when using the Cisco Integrated Management Controller. If the server has ADDDC and a VLS event occurred, then this is working as designed to prevent uncorrectable errors.
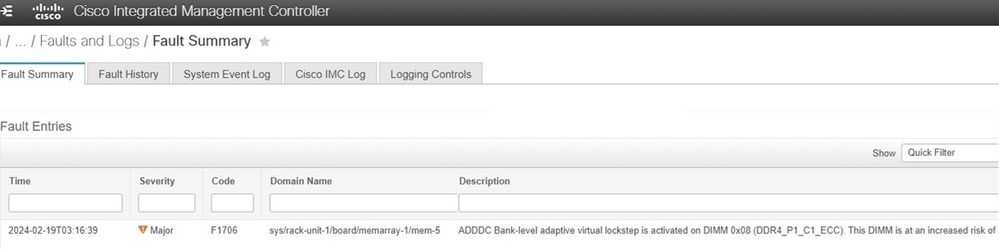
Troubleshooting Steps
- Verify no other DIMM faults are present for instance and Uncorrectable Error.
- Schedule a maintenance window.
- Place a host in maintenance mode, and reboot the server to attempt permanent repair of the DIMM using Post Package Repair (PPR).
UCSM Reboot Steps
Note: You can reboot the server from the OS as well. This example uses the reboot option from the server UI.
Navigate to your UCS Manager web Interface.
Blade Server
Navigate to Equipment > Chassis > Server X.
Integrated Server
Navigate to Equipment > Rack-Mounts > Server X.
Click KVM console.
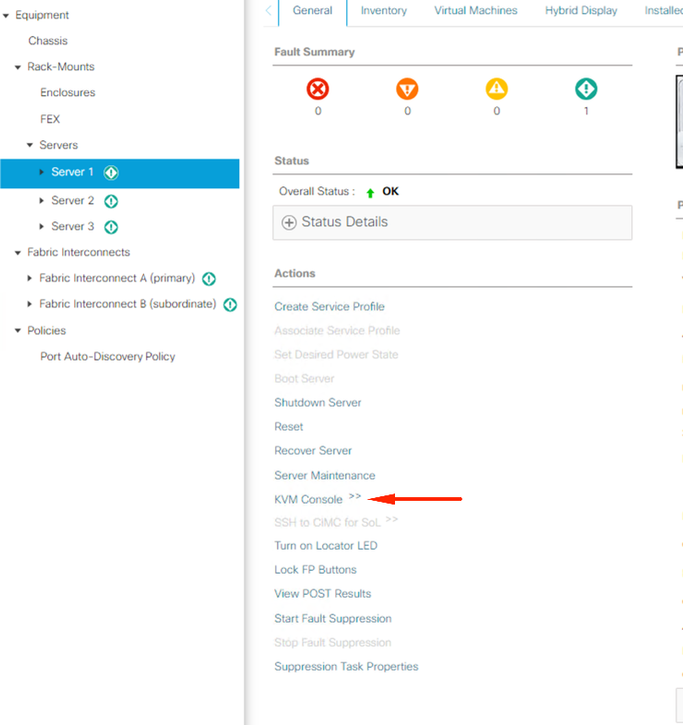
on the KVM windows, click server actions, select Reset, and click OK.
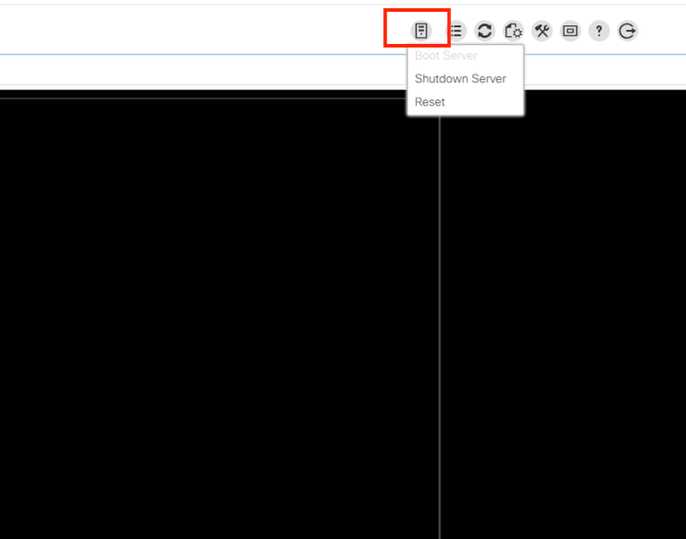
Monitor in the KVM the reboot process, and ensure the OS boots up correctly.
IMM Reboot Steps
Navigate to the Servers Tab, identify the server, and click the Action (three dots) menu.
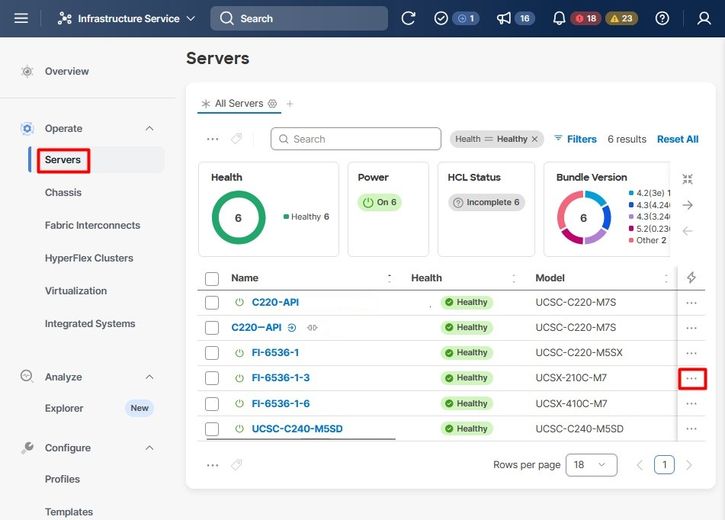
Next, select the Power menu and then Power Cycle option.
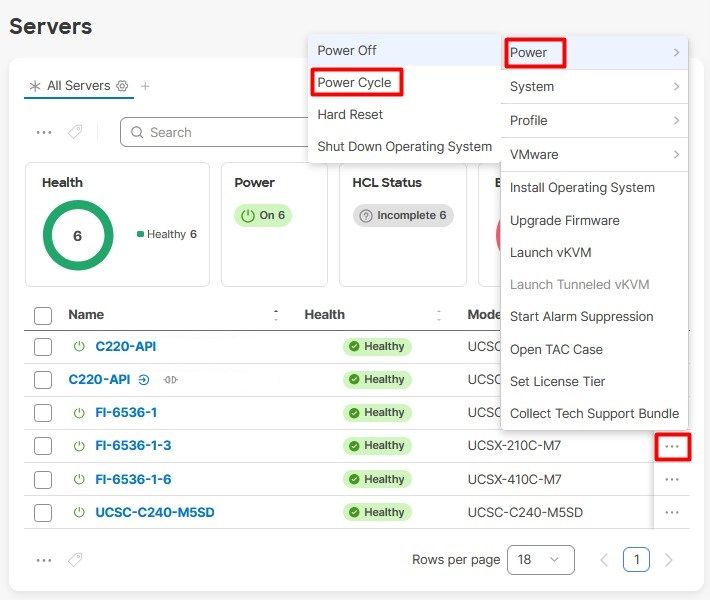
Click the Power Cycle button to confirm the action.
Validate the progress under the Requests menu.
CIMC Reboot Steps
Navigate to the Host Power option and select Power Cycle.
Launch the KVM to monitor the reboot process, and ensure the OS boots up correctly.
Monitor for New Faults
If no errors occur after reboot meaning that there is no other RAS event or fault related to the DIMM, PPR was successful and the server can be put back into use.
If new ADDDC events occur, repeat the reboot process outlined in the previous steps to perform additional permanent repairs with PPR.
If an Uncorrectable Error, or inoperable fault occurs after reboot, the fault indicates that a memory needs to be replaced.
Note: Please open a case with Cisco TAC to replace the DIMM if you encounter any of these faults.
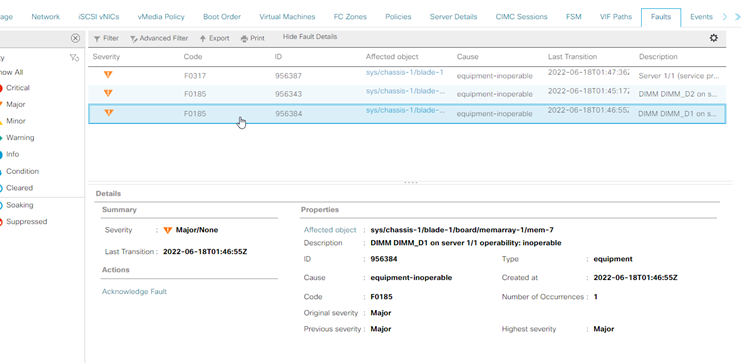
UCS Manager Uncorrectable Memory Error
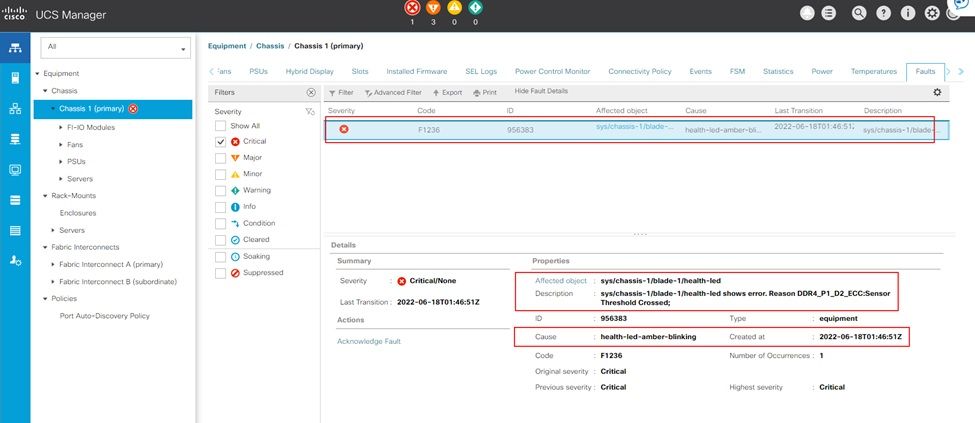
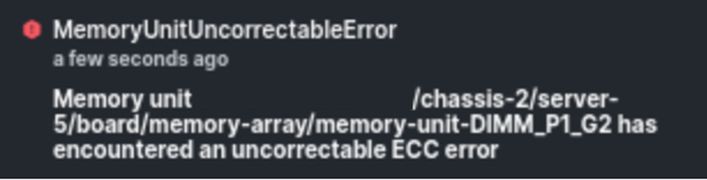
IMM Memory Uncorrectable Error
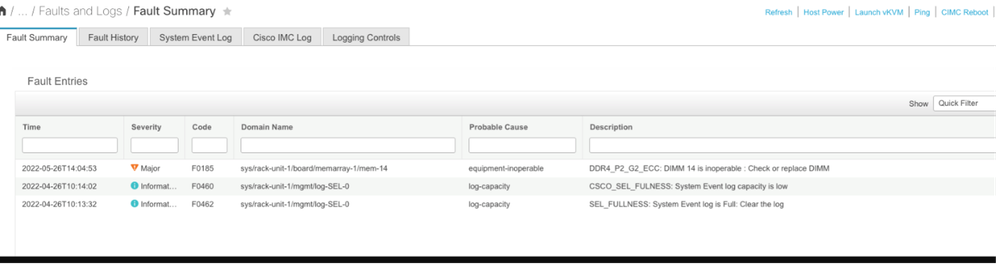
Uncorrectable error fault. The fault indicates the DIMM has an uncorrectable error and needs to be replaced.
CIMC Uncorrectable Memory Error
Related Information
 Feedback
Feedback