Understand High CPU Utilization Reported by vManage for vEdge 5000/2000/1000/100B and vEdge Cloud Platforms
Available Languages
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Contents
Introduction
This document describes why you might see high CPU usage reported in vManage for vEdge 5000/2000/1000/100B and vEdge Cloud platforms despite the performance of the platforms being normal with no high CPU reported as viewed in top.
Understand High CPU Utilization that is Reported on vEdge 5000/2000/1000/100B and vEdge Cloud Platforms
With the 17.2.x and later releases, higher CPU and memory consumption for vEdge and vEdge Cloud platforms can be observed. This is noticed on the vManage Dashboard for a given device. In some cases, this also leads to an increased number of alerts and warnings in vManage.
Explanation
The reason for reported high CPU usage when the device performs normally with normal, low, or no load is due to a change in the formula used in order to calculate usage. With the 17.2 releases, CPU utilization is computed based on the Load Average from show system status on the vEdge.
vManage shows real-time CPU utilization for a device. It pulls the 1 Minute Average [min1_avg] and 5 Minutes Average [min5_avg] based on historical data. Load Average, by definition, includes various things and not just CPU cycles that contribute to the utilization calculation. For example, IO wait time, process pending time, and other values are considered when you present this value for the platform. In this case, you ignore the values shown for the CPU states and CPU values in the top command from vShell.
Here is an example on how CPU utilization, which is actually the 1 minute load average, gets calculated and shown in the vManage dashboard:
When you check load from a vEdge CLI, this can be seen:
vEdge# show system status | include Load Load average: 1 minute: 3.10, 5 minutes: 3.06, 15 minutes: 3.05 Load average: 1 minute: 3.12, 5 minutes: 3.07, 15 minutes: 3.06 Load average: 1 minute: 3.13, 5 minutes: 3.08, 15 minutes: 3.07
Load average: 1 minute: 3.10, 5 minutes: 3.07, 15 minutes: 3.05
In this case, CPU utilization is computed based on Load-Average / # of Cores (vCPUs). For this example, the node has 4 cores. The load-average is then converted by a factor of 100 before you divide by the number of cores. When you average the Load Average from all cores and multiply by 100, you arrive on a value of ~310. Take this value and divide by 4 yields, a CPU reading of 77.5% CPU, which aligns with the value seen in the real-time graph in vManage captured around the time the CLI output was collected and as shown in the image.
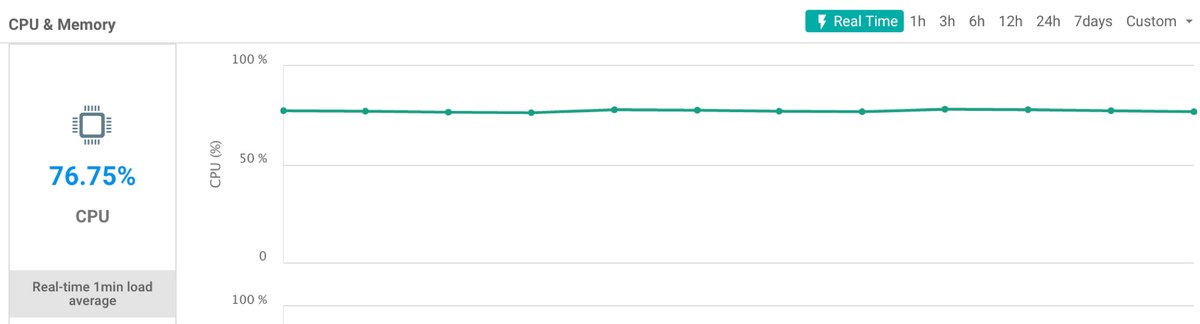
In order to see the load averages and the number of CPU cores in the system, the output of top can be consulted from vShell on the device.
In the example here, the vEdge contains 4 vCPUs. The first core (Cpu0) is used for Control (seen through the lower user utilization) while the remaining 3 cores are used for Data:
top - 01:14:57 up 1 day, 3:15, 1 user, load average: 3.06, 3.06, 3.08 Tasks: 219 total, 5 running, 214 sleeping, 0 stopped, 0 zombie Cpu0 : 1.7%us, 4.0%sy, 0.0%ni, 94.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu1 : 56.0%us, 44.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu2 : 54.2%us, 45.8%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu3 : 59.3%us, 40.7%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 7382664k total, 2835232k used, 4547432k free, 130520k buffers Swap: 0k total, 0k used, 0k free, 587880k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 978 root 20 0 3392m 664m 127m R 100 9.2 1635:21 fp-um-2 692 root 20 0 3392m 664m 127m R 100 9.2 1635:18 fp-um-1 979 root 20 0 3392m 664m 127m R 100 9.2 1634:51 fp-um-3 694 root 20 0 1908m 204m 131m S 1 2.8 15:29.95 ftmd 496 root 20 0 759m 72m 3764 S 0 1.0 1:31.50 confd
In order to get the number of CPUs from the vEdge CLI, this command can be used:
vEdge# show system status | display xml | include total_cpu
<total_cpu_count>4</total_cpu_count>
Another example of the calculation for the value shown in vManage on vEdge 1000 is provided here. After you issue top from vShell, l is interested in order to display the load for all cores:
top - 18:19:49 up 19 days, 1:37, 1 user, load average: 0.55, 0.71, 0.73
Since a vEdge 1000 only has one CPU core available, the load reported here is 55% (0.55*100).
High CPU Usage with fp-um Process
You can also sometimes notice from top that the fp-um process runs high and shows up to 100% CPU. This is expected on the CPU cores that are used for Data Plane processing.
From the top command referenced earlier, 3 cores operates at 100% CPU and 1 core shows normal utilization:
top - 01:14:57 up 1 day, 3:15, 1 user, load average: 3.06, 3.06, 3.08 Tasks: 219 total, 5 running, 214 sleeping, 0 stopped, 0 zombie Cpu0 : 1.7%us, 4.0%sy, 0.0%ni, 94.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu1 : 56.0%us, 44.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu2 : 54.2%us, 45.8%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu3 : 59.3%us, 40.7%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 7382664k total, 2835232k used, 4547432k free, 130520k buffers Swap: 0k total, 0k used, 0k free, 587880k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 978 root 20 0 3392m 664m 127m R 100 9.2 1635:21 fp-um-2 692 root 20 0 3392m 664m 127m R 100 9.2 1635:18 fp-um-1 979 root 20 0 3392m 664m 127m R 100 9.2 1634:51 fp-um-3 ...
This first core (Cpu0) is used for Control and the three remaining cores used for Data. As you can see in the process list, the fp-um process uses those resources.
fp-um is a process that uses a poll-mode driver, which means that it sits and polls the underlying port for packets constantly so that it can process any frame as soon as it is received. This process handles forwarding and is equivalent to fast-path forwarding in the vEdge 1000, vEdge 2000, and vEdge 100. This poll-mode architecture is used by Intel for efficient packet processing based on Data Plane Development Kit (DPDK) framework. Because packet forwarding is implemented in a tight loop, CPU remains at or close to 100% at all times. Although this is done, no latency is introduced through these CPU's as this is expected behavior.
Background information on DPDK polling can he found here.
The vEdge Cloud and vEdge 5000 platforms use the same forwarding architecture and exhibit the same behavior in this regard. Here is an example from a vEdge 5000 pulled from the top output. It has 28 cores, of which 2 (Cpu0 and Cpu1) are used for Control (like the vEdge 2000) and 26 are used for Data.
top - 02:18:30 up 1 day, 7:33, 1 user, load average: 26.24, 26.28, 26.31 Tasks: 382 total, 27 running, 355 sleeping, 0 stopped, 0 zombie Cpu0 : 0.7%us, 1.3%sy, 0.0%ni, 98.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu1 : 0.7%us, 1.3%sy, 0.0%ni, 98.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu2 : 79.4%us, 20.6%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu3 : 73.4%us, 26.6%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu4 : 73.4%us, 26.6%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu5 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu6 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu7 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu8 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu9 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu10 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu11 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu12 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu13 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu14 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu15 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu16 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu17 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu18 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu19 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu20 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu21 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu22 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu23 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu24 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu25 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu26 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Cpu27 :100.0%us, 0.0%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 32659508k total, 10877980k used, 21781528k free, 214788k buffers Swap: 0k total, 0k used, 0k free, 1039104k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2028 root 20 0 12.1g 668m 124m R 100 2.1 1897:21 fp-um-3 2029 root 20 0 12.1g 668m 124m R 100 2.1 1897:22 fp-um-4 2030 root 20 0 12.1g 668m 124m R 100 2.1 1897:12 fp-um-5 2031 root 20 0 12.1g 668m 124m R 100 2.1 1897:22 fp-um-6 2032 root 20 0 12.1g 668m 124m R 100 2.1 1897:22 fp-um-7 2034 root 20 0 12.1g 668m 124m R 100 2.1 1897:22 fp-um-9 2035 root 20 0 12.1g 668m 124m R 100 2.1 1897:21 fp-um-10 2038 root 20 0 12.1g 668m 124m R 100 2.1 1897:21 fp-um-13 2040 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-15 2041 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-16 2043 root 20 0 12.1g 668m 124m R 100 2.1 1897:22 fp-um-18 2045 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-20 2052 root 20 0 12.1g 668m 124m R 100 2.1 1897:18 fp-um-27 2033 root 20 0 12.1g 668m 124m R 100 2.1 1897:21 fp-um-8 2036 root 20 0 12.1g 668m 124m R 100 2.1 1897:21 fp-um-11 2037 root 20 0 12.1g 668m 124m R 100 2.1 1897:21 fp-um-12 2039 root 20 0 12.1g 668m 124m R 100 2.1 1897:09 fp-um-14 2042 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-17 2044 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-19 2046 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-21 2047 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-22 2048 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-23 2049 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-24 2050 root 20 0 12.1g 668m 124m R 100 2.1 1897:22 fp-um-25 2051 root 20 0 12.1g 668m 124m R 100 2.1 1897:23 fp-um-26 1419 root 20 0 116m 5732 2280 S 0 0.0 0:02.00 chmgrd 1323 root 20 0 753m 70m 3764 S 0 0.2 1:51.20 confd 1432 root 20 0 1683m 172m 134m S 0 0.5 0:58.91 fpmd
Here, the Load Average is always high because 26 out of the 28 processors run at 100% due to the fp-um process.
Conclusion
The reported CPU usage in vManage for 17.2.x releases prior to 17.2.7 is not the actual CPU usage but is instead calculated based on the Load Average. This may lead to confusion in understanding the reported value and lead to false alarms related to high CPU while the platform operates normally with normal, low, or no actual traffic/network load.
This behavior is changed/modified with the 17.2.7 and 18.2 releases such that the CPU reading can now be accurate based on the cpu_user reading from top.
The issue is also mentioned in the 17.2 release notes.
Contributed by Cisco Engineers
- Shankar VemulapalliCisco Engineering
- Brandon LynchCisco Engineering
- Danny De RidderCisco TAC Engineer
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)