Introduction
This document describes a problem with configuration-db restoration fails in vManage cluster DR setup.
Problem
Restore vManage NMS from Backup: configuration-db restoration fails in vmanage cluster DR setup
From the CLI, use the request nms configuration-db restore path command. This command restores the configuration database from the file locate datapath. In this example, the destination is the standby vManage NMS. Run these commands on the standby vManage NMS:
vmanage-1# request nms configuration-db restore path /home/admin/cluster-backup.tar.gz
Configuration database is running in a cluster mode
!
!
!
line omitted
!
!
!
.................... 80%
.................... 90%
.................... 100%
Backup complete.
Finished DB backup from: 30.1.1.1
Stopping NMS application server on 30.1.1.1
Stopping NMS application server on 30.1.1.2
Stopping NMS application server on 30.1.1.3
Stopping NMS configuration database on 30.1.1.1
Stopping NMS configuration database on 30.1.1.2
Stopping NMS configuration database on 30.1.1.3
Reseting NMS configuration database on 30.1.1.1
Reseting NMS configuration database on 30.1.1.2
Reseting NMS configuration database on 30.1.1.3
Restoring from DB backup: /opt/data/backup/staging/graph.db-backup
cmd to restore db: sh /usr/bin/vconfd_script_nms_neo4jwrapper.sh restore /opt/data/backup/staging/graph.db-backup
Successfully restored DB backup: /opt/data/backup/staging/graph.db-backup
Starting NMS configuration database on 30.1.1.1
Waiting for 10s before starting other instances...
Starting NMS configuration database on 30.1.1.2
Waiting for 120s for the instance to start...
NMS configuration database on 30.1.1.2 has started.
Starting NMS configuration database on 30.1.1.3
Waiting for 120s for the instance to start...
NMS configuration database on 30.1.1.3 has started.
NMS configuration database on 30.1.1.1 has started.
Updating DB with the saved cluster configuration data
Successfully reinserted cluster meta information
Starting NMS application-server on 30.1.1.1
Waiting for 120s for the instance to start...
Starting NMS application-server on 30.1.1.2
Waiting for 120s for the instance to start...
Starting NMS application-server on 30.1.1.3
Waiting for 120s for the instance to start...
Removed old database directory: /opt/data/backup/local/graph.db-backup
Successfully restored database
vmanage-1#
Step 1. Config-db should restore with those logs but there is a scenario where config_db backup fails with these error messages.
vmanage-1# request nms configuration-db restore path /home/admin/cluster-backup.tar.gz
Configuration database is running in a cluster mode
!
!
line ommited
!
!
2020-08-09 17:13:48.758+0800 INFO [o.n.k.i.s.f.RecordFormatSelector] Selected RecordFormat:StandardV3_2[v0.A.8] record format from store /opt/data/backup/local/graph.db-backup
2020-08-09 17:13:48.759+0800 INFO [o.n.k.i.s.f.RecordFormatSelector] Format not configured. Selected format from the store: RecordFormat:StandardV3_2[v0.A.8]
.................... 10%
.................... 20%
.................... 30%
.................... 40%
.................... 50%
.................... 60%
.................... 70%
...............Checking node and relationship counts
.................... 10%
.................... 20%
.................... 30%
.................... 40%
.................... 50%
.................... 60%
.................... 70%
.................... 80%
.................... 90%
.................... 100% Backup complete.
Finished DB backup from: 30.1.1.1
Stopping NMS application server on 30.1.1.1
Stopping NMS application server on 30.1.1.2
Could not stop NMS application-server on 30.1.1.2
Failed to restore the database
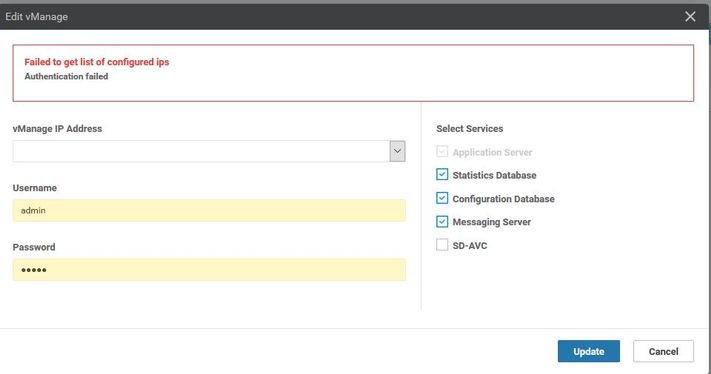
Step 2. In the mentioned failure, scenario Under cluster management page in vmanage, navigate to Administrator > Cluster management > Select neighbor vmanage (...) > Edit

While the vManage in cluster management is edited, the error received is: "Failed to get a list of configured ips -Authentication failed"'
Solution
During the config-db restore operation in a vManage cluster, it is required to start/stop services on the remote nodes. This is done by Netconf requests made to the remote node in the cluster.
If control connection present between vmanages in the cluster then vmanage try to authenticate the remote node with the public key of the remote node to authenticate the Netconf request, which is similar to control connections between devices. If it is not there then it falls back to the credentials stored in the database table which was used to form the cluster.
The issue we have encountered is that the password got changes via CLI however the cluster management password in the database not updated. So whenever we change the password of netadmin account that is used to create the cluster initially, you need to update the password with the help of the edit operation of cluster-management too. These are the additional steps you need to follow.
- Log in to each vmanages GUI.
- Navigate to Administrator > Cluster management > Select respective vManage (...) > Edit , as shown in the image.
- Update password equivalent to CLI.

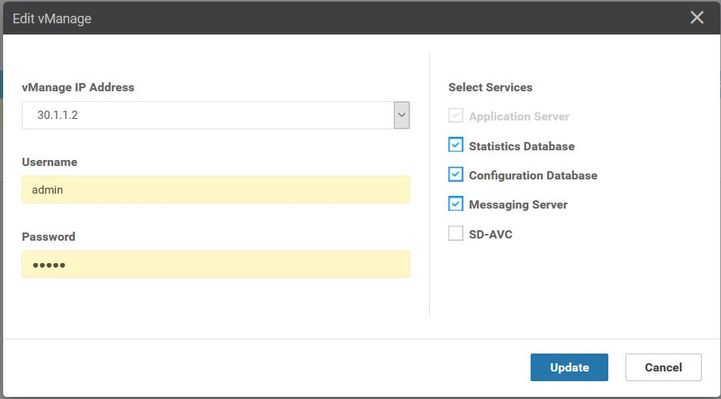
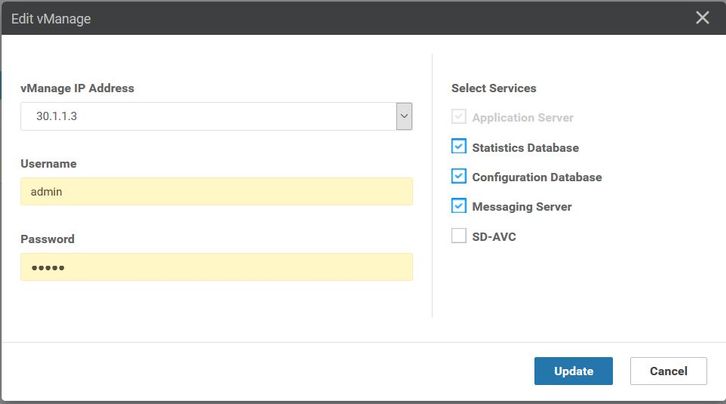
Note: Rollback of the password from CLI is not feasible in this scenario from the CLI.
Best Practice
The best practice to change vManage password in the cluster is to navigate to Administrator > Manage users > update password.
This procedure updates the password in all 3 vManages in the cluster as well as the cluster management password as well.
Related Information
 Feedback
Feedback