Load Balancing Logic on Cisco Meeting Server
Available Languages
Download Options
Bias-Free Language
The documentation set for this product strives to use bias-free language. For the purposes of this documentation set, bias-free is defined as language that does not imply discrimination based on age, disability, gender, racial identity, ethnic identity, sexual orientation, socioeconomic status, and intersectionality. Exceptions may be present in the documentation due to language that is hardcoded in the user interfaces of the product software, language used based on RFP documentation, or language that is used by a referenced third-party product. Learn more about how Cisco is using Inclusive Language.
Contents
Introduction
This document describes the load balancing logic of the Cisco Meeting Server (CMS) (formerly Acano product) which is covered on the Load Balancing white paper. This document visualizes this process in a flowchart and goes in more detail on the selection algorithm.
Prerequisites
Requirements
Cisco recommends that you have knowledge of these topics:
- Cisco Meeting Server Call Bridge component (and clustering of it)
- Cisco Meeting Server API configuration
Components Used
The information in this document is based on Cisco Meeting Server, Version 2.4.x.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, ensure that you understand the potential impact of any command.
What is the Load Balancing Algorithm of the CMS?
Load balancing has been introduced in Version 2.1 of CMS in order to make efficient use of conference resources. It tries to minimize the number of distribution calls between the Call Bridges that host the same space. This mechanism is based on the Replaces header in Session Initiation Protocol (SIP) and is supported in Cisco Unified Communications Manager (CUCM) as the call control. It is also supported with Expressway Version X8.11 (or later), in combination with a CMS Version 2.4 or later. CMA calls (both thick client and WebRTC type) can be load balanced as well from CMS Version 2.3 onwards.
Note: Load balancing of Lync/Skype calls is not supported in any CMS version at this moment in time and thus this flowchart does not apply.
Note: The Load Balancing logic only applies for calls to CMS spaces and thus not for gateway calls (P2P calls) or dual-home calls at this moment in time.
The load balancing process is highlighted in the white paper in the section How load balancing uses the settings under Configuring Call Bridges for load balancing incoming calls. It is shown in text format and is visualized here in the flowchart (download ).
The flowchart makes use of some abbreviations and terminology:
- CB = Call Bridge
- ExistingConferenceLoadLimit = existingConferenceLoadLimitBasisPoints * loadLimit
(by default the existingConferenceLoadLimitBasisPoints equals 8000, which corresponds to 80%) - NewConferenceLoadLimit = newConferenceLoadLimitBasisPoints * loadLimit
(by default the newConferenceLoadLimitBasisPoints equals 5000, which corresponds to 50%)
If MediaProcessingLoad is referenced, it is seen in regards to that particular Call Bridge where the call has landed. This load value can be verified with an API GET on /system/load in real-time and gives a representation of the actual load processed by this Call Bridge at that moment in time.
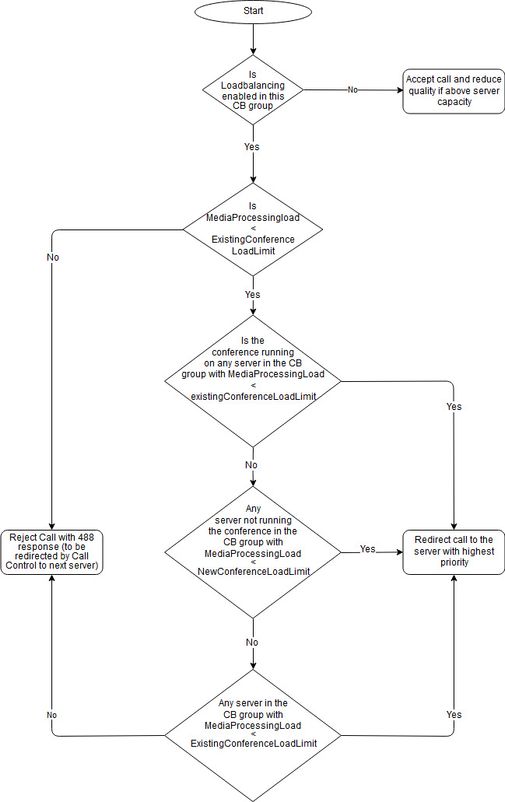
If you end up your call in the lower rightmost box, it redirects the call to the server with the highest priority. This can be the Call Bridge server itself or another server within the Call Bridge Group on which the call landed. In case no decision is made based on the load and whether the space is active already on a Call Bridge, there is a tie with multiple Call Bridges. In that case, the final decision is made based on the default Call Bridge preference that is assigned to each space. This Call Bridge preference is allocated at the creation of the space automatically and is not configurable as it is based on the hash values of several attributes. This results in an even (random) distribution for different spaces across all Call Bridges.
In order to see the Call Bridge preference for a particular space, you would need to verify this in the CMS event log as shown in these examples.
Examples of the Load Balancing Algorithm
This section contains examples of possible scenarios and how the event log of the CMS where the call landed shows the load balancing process as covered in the flowchart.
For these examples, a lab setup was used with a Call Bridge Group of three Call Bridges. The existingConferenceLoadLimitBasisPoints and newConferenceLoadLimitBasisPoints configurations were set to their default values corresponding to 80% and 50% respectively of the loadLimit value.
In order to check the current MediaProcessingLoad on a particular Call Bridge, you can browse to https://<ip-or-fqdn-of-callbridge>:<webadmin-port>/api/v1/system/load and log in with an API or admin account as displayed on the picture.
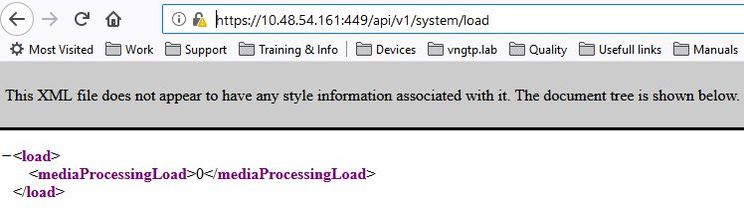
Example 1: No Load on any Call Bridge
In this example, there are no calls active at any of the Call Bridges. Thus the MediaProcessingLoad of all servers equals zero.
When you place a call to one of the Call Bridges (cluster1 here) (with load balancing enabled on both the CMS and call control devices), you can see the event log on the Call Bridge where the call landed:
2018-12-29 10:51:29.490 Info call 75: incoming SIP call from "sip:1060@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 10:51:29.565 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 10:51:29.712 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replacing call 'f8eeea46e0f0790a@10.10.50.13' to conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 on server 'cluster3' 2018-12-29 10:51:29.876 Info call 75: ending; remote SIP cancel (remote cancel) - not connected after 0:00
in which you can see the replace query lines for each of the Call Bridges in your Call Bridge Group that show us the load balancing algorithm which is split up in three sections:
- priority - the Call Bridge preference of that space
- load level - the load level of that Call Bridge at that moment in time
- conference is running - boolean whether the space is active on that Call Bridge
As no calls were placed at that time into the system, there is no load on any of the systems (all 0) and the conference is not running anywhere (all 0). In that regards, the final decision is made based on the Call Bridge preference of the space. A lower priority is preferred and thus the call is replaced here to Call Bridge named cluster3 as seen by the replacing call line.
On Call Bridge cluster3, you can see the event log lines that indicate this replacing call (as well as which Call Bridge it came from (cluster1 here) and the same conference ID and call ID):
2018-12-29 10:51:29.784 Info replacing call 'f8eeea46e0f0790a@10.10.50.13' from server 'cluster1' into conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 2018-12-29 10:51:29.787 Info call 193: outgoing SIP call to "1060@steven.lab" from space "Steven Janssens's space" 2018-12-29 10:51:29.792 Info call 193: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 10:51:29.909 Info call 193: compensating for far end not matching payload types 2018-12-29 10:51:29.911 Info participant "1060@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
In case the call already landed on the Call Bridge with the lowest priority value (cluster3 here for this space), then you can still see the same replace query lines in the event log but it indicates now that it uses the local server and there is no replacing call line:
2018-12-29 11:05:25.202 Info call 194: incoming SIP call from "sip:1060@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 11:05:25.233 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 11:05:25.376 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 11:05:25.378 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 11:05:25.378 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 11:05:25.380 Info call 194: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 11:05:25.404 Info participant "1060@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Example 2: Already Participants on the Space in the Call Bridge Group
In this example, the space is already active within the Call Bridge Group as endpoint 1060@steven.lab called into the space as shown on example 1.
There are two situations in this case:
1. The Call Bridge that hosts this space has a load lower than the existing conference threshold and thus is able to accept the call.
2. The Call Bridge that hosts this space has a load higher than the existing conference threshold and thus CMS tries to replace the call to another Call Bridge.
Scenario 1. Active Space and Load Lower than Existing Conference Threshold (80%)
In case the call landed on a Call Bridge where the space was not yet active, the event log shows now that the space is active on Call Bridge with name cluster3. As the space is active there and the load on that server is lower than the existing threshold (load level: 0), the call is replaced.
2018-12-29 11:48:17.419 Info call 82: incoming SIP call from "sip:800999@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 11:48:17.477 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 1) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster3' (priority: 0, load level: 0, conference is running: 1) 2018-12-29 11:48:17.607 Info replacing call '4c28197eaebba178@10.10.2.250' to conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 on server 'cluster3'
The conference is running takes preference to the priority first so if there would have been multiple candidates with a load level under the existing conference threshold, then it would come down to the Call Bridge preference as per the priority value. However, that is not the case here.
Scenario 2. Active Space and Load Higher than Existing Conference Threshold (80%)
In this case, the call is not replaced with that Call Bridge but it rather looks for another Call Bridge within the group that has some resources still available. First, it checks if there are Call Bridges with a load lower than 50% (new conference threshold) and loads those ones first. If there are none under this threshold, it checks if there are still available under 80% (existing conference threshold).
If the load on Call Bridge cluster3 is checked after the calls of examples 1 and 2 (scenario 1), it shows a load of 2000.
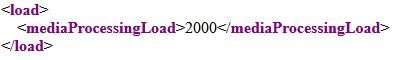
Assume, that the loadLimit for that Call Bridge cluster3 was set to 2250 (just as an example), then this Call Bridge is over the existing conference threshold as that is calculated as 0.80 * 2250 = 1800
There are two cases still to make differentiation in this scenario.
Case 1: Multiple Servers in the Group still with a Load Lower than New Conference Threshold (50%)
The other two servers in the group do not have any calls handled still so the load is still at 0 and thus they could both handle the call. The end decision thus is made based on the Call Bridge preference for this space. As Call Bridge cluster3 is already full, the systems pick the lowest priority out of cluster1 and cluster2 which is cluster1 in this case.
2018-12-29 12:11:03.211 Info call 86: incoming encrypted SIP audio call from "sip:2001@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 12:11:03.263 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 12:11:03.405 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 12:11:03.412 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:11:03.412 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 12:11:03.415 Info call 86: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 12:11:03.434 Info participant "2001@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Notice that the load level: 2 on the cluster3 Call Bridge indicates that it went over the existing conference threshold, so even though the space was active there the call is not load balanced to that server. Instead, it looks at the lowest space priority of the other Call Bridges with a load level: 0 (meaning lower than 50% usage), which is cluster1 in this case.
Case 2: Only One Server in a Group with a Load Lower than New Conference Threshold (50%) or Existing Conference Threshold (80%)
After the last call (and calls to other space to cluster2), the described loads were seen on the Call Bridges:
- cluster 1 - 1200
- cluster 2 - 400
- cluster 3 - 4000
Assume now that the loadLimit as set on cluster1 Call Bridge would be 1300, then this Call Bridge is over the new conference threshold as that is calculated as 0.50 * 1300 = 650 as well as over the existing conference threshold of 0.80 * 1300 = 1040.
In case a new WebRTC call would come in now on Call Bridge cluster3 for that same space, the space is active both on cluster1 and cluster3 but both are over the existing conference threshold and thus it looks for another server under the new conference threshold (50%) or existing conference threshold (80%). In this case, only cluster2 would still be under the existing conference threshold, but it is over the new conference threshold already because of another call to another space handled on cluster2 Call Bridge.
2018-12-29 12:45:33.162 Info instantiating user "guest1685904798@cluster.steven.lab" 2018-12-29 12:45:33.162 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 2, conference is running: 1) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster2' (priority: 2, load level: 1, conference is running: 0)
Cluster2 has been set up with a loadLimit value of 600 here. With 400 as the current load before the new call came in, it is over the new conference threshold of 0.5 * 600 = 300 but it is still under the existing conference limit of 0.8 * 600 = 480. Thus this shows up in the replace query as load level: 1 (instead of 2 when the Call Bridge is over the 80% threshold).
Example 3: Call Landing on Call Bridge over the Existing Conference Threshold
In this case, the load balancing algorithm does not take place as it would be better to send a 488 Response back to the call control device which can then decide to try to route the call to a different Call Bridge within the group (which can be under the 80% limit) or to even route it to a different Call Bridge group if the current group is out of resources (as a fallback option).
The event log does not explicitly show this part in much detail as it just reports that it went over the capacity:
2018-12-29 12:49:13.352 Info call 88: incoming encrypted SIP call from "sip:2020@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 12:49:13.399 Info call 88: ending; local teardown, system participant limit reached - not connected after 0:00
Once the call is sent over to a different Call Bridge that can handle the load (cluster2 for example), the same load balancing algorithm is shown:
2018-12-29 12:49:13.434 Info call 624: incoming encrypted SIP call from "sip:2020@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab"
2018-12-29 12:49:13.475 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:49:13.614 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:49:13.614 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:49:13.618 Info call 624: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 12:49:13.621 Info call 624: starting DTLS UDT media negotiation (as initiator) 2018-12-29 12:49:13.640 Info participant "2020@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Note: In case of gateway calls, the CMS returns a 486 SIP error message instead. By default CUCM stops the routing as per the Service Parameter of Stop Routing on User Busy Flag so you might want to change this setting to allow fallback for gateway calls to your other callbridges.
Revision History
| Revision | Publish Date | Comments |
|---|---|---|
1.0 |
30-Apr-2019 |
Initial Release |
Contributed by Cisco Engineers
- Steven JanssensCisco TAC Engineer
- Nart OmatCisco TAC Engineer
 Feedback
FeedbackContact Cisco
- Open a Support Case

- (Requires a Cisco Service Contract)