Introduction
This document describes the process to redeploy an offline node in Cisco Hyperflex clusters.
Prerequisites
Requirements
This is supported only for Hyperflex clusters deployed from Intersight and starting from version 5.0(2b). Clusters deployed via Hyperflex installer and imported to Intersight are not supported for this feature yet.
Type of scenarios supported for this Intersight feature:
- FI/standard Cluster, Strech Cluster, Edge cluster and DC-No-FI cluster
- Clusters with SED (Self Encrypted Drives)
- Clusters deployed from Intersight only
- ESXi and SCVM redeploy
- Only SCVM redeploy
Not Supported Scenarios
- 1GbE HyperFlex Edge and Stretch clusters.
- Clusters imported to Intersight
Licensing
Intersight Essentials or superior license is required for HyperFlex node redeployment. All the servers in the HyperFlex cluster must be claimed and configured with Intersight Essentials or superior license.
Components Used
- Cisco Intersight
- Cisco UCSM (optional)
- Cisco UCS Servers
- Cisco Hyperflex Cluster version 5.0(2c)
- VMWare ESXi
- VMware vCenter
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, ensure that you understand the potential impact of any command.
Background Information
Maintaining a cluster healthy becomes a priority for multiple reasons but the most important is redundancy for the sake of data integrity in the Hypercoverge storage solution. There are multiple scenarios that require ESXi and SCVM (Storage Controller Virtual Machine) redeploy simultaneously such as replacing the boot drive in converge nodes.
For clusters deployed from Intersight you can redeploy the SCVM to add it back to the Hyperflex cluster, this activity can be now executed without TAC assistance via Intersight.

Warning: It is important to stress that not doing this process successfully can lead into clusters having multiple unexpected issues such as future cluster upgrades failures and cluster expansions failing.
Configuration
For this example we use a 3 Node Edge cluster named Medellin which has gotten node 3 corrupted due to a M.2 disk failure
From Intersight our starting point assumes a couple of aspects are already covered:
- M.2 Storage has already been replaced
- Hyperflex cluster is still unhealthy since it has that node offline
Cluster Node Offline Validation
You can see cluster is unhealthy as explained and you need to recover the node that is offline now that the M.2 issue has been fixed
From Intersight go to Infrastructure Service > Hyperflex Cluster > Overview > Events. You are able to see resiliency status
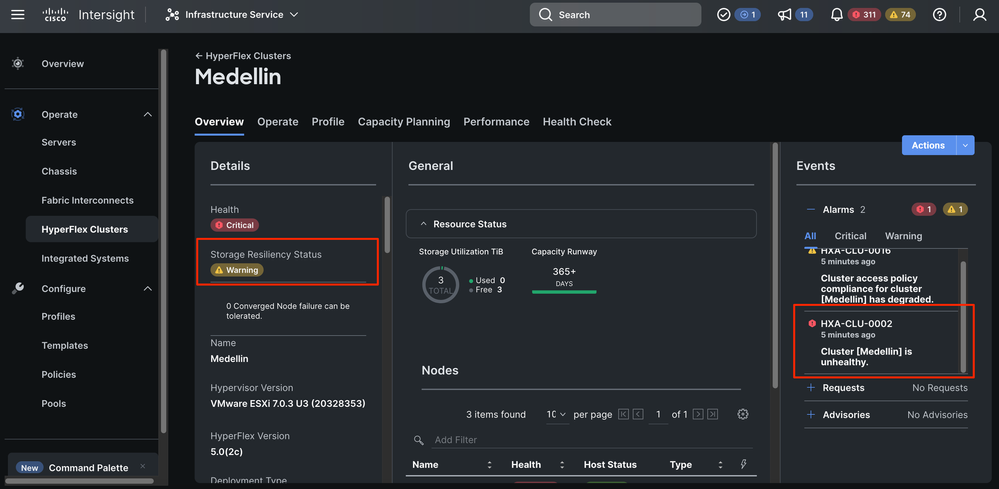
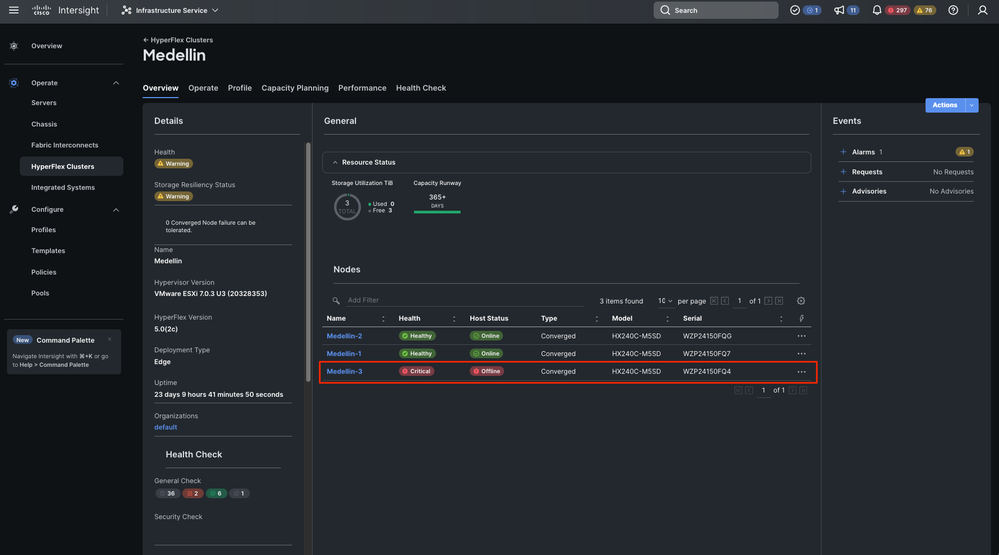
In the same Overview tab you can see what specific node is offline too
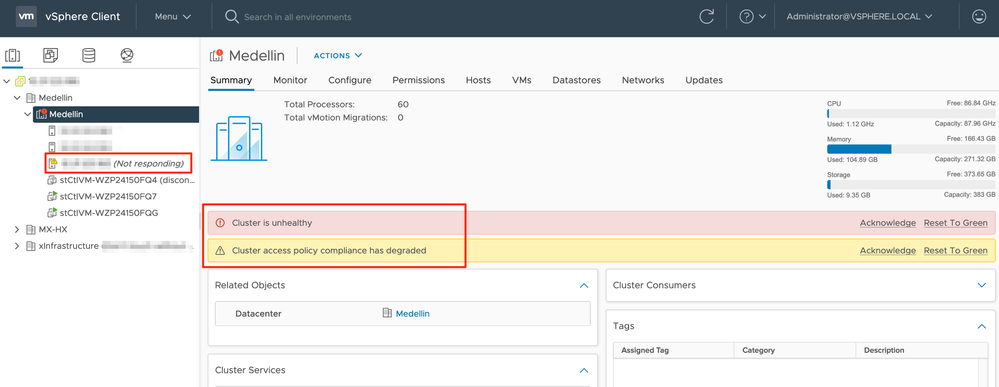
From vCenter we also get an alert about cluster being unhealthy
Finally from CLI you can also assest the cluster status:
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : WARNING
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 0
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 30.4 GiB
Free Capacity : 3.0 TiB
Compression Savings : 62.06%
Deduplication Savings : 0.00%
Total Savings : 62.06%
# of Nodes Configured : 3
# of Nodes Online : 2
Data IP Address : 169.254.218.1
Resiliency Health : WARNING
Policy Compliance : NON_COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 0
# of persistent device failures tolerable : 1
# of cache device failures tolerable : 1
Zone Type : Unknown
All Flash : No
Redeploy Steps
Step 1. Reinstall the ESXi OS. For that you can go to Servers > Select the Server > Options (three dots) > Select Launch the KVM.
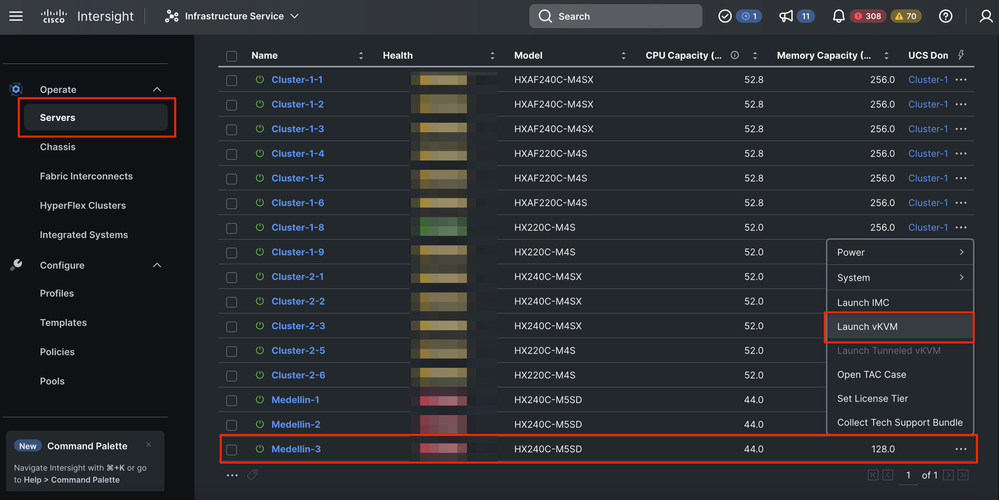
Caution: You must download a Cisco Hyperflex custom image for the same exact ESXi version other nodes are running in the cluster. You can download it from here
Once KVM is launched Navigate to Virtual Media > Select Activate Virtual Devices

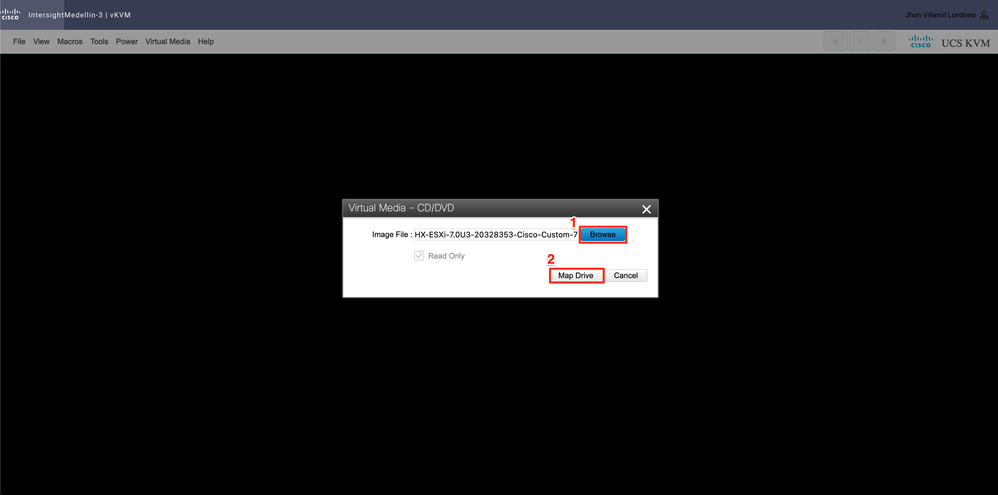
Then Select Browse > Select the Hyperflex ESXi iso image from your local computer > Select Map Drive
Navigate to Power > depending on the status of the server select either Power on System or Reset System or Power Cycle System 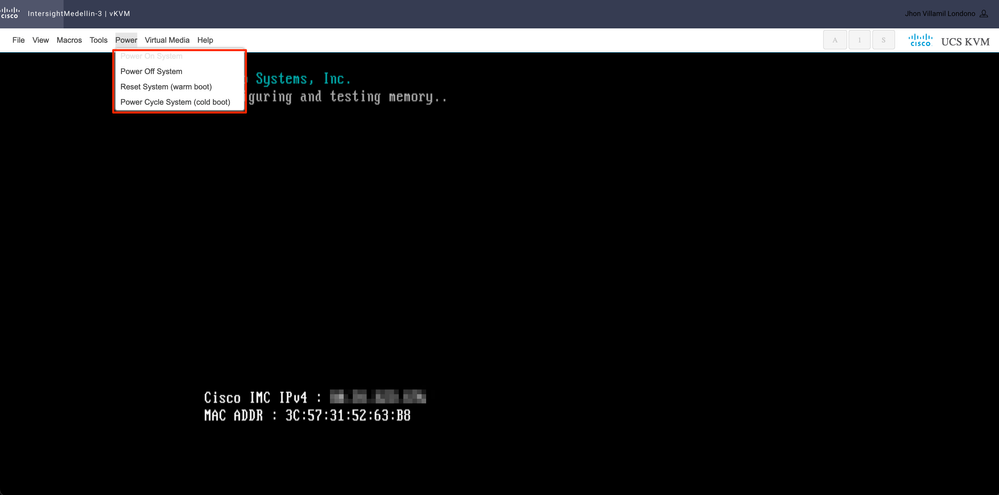
Tip: Reset System (warm boot) reboots the system without powering it off whereas Power Cycle System (cold boot)Turns off system and then back on. In this scenario with SCVM corrupted and ESXi being reinstalled both options meet the same purpose
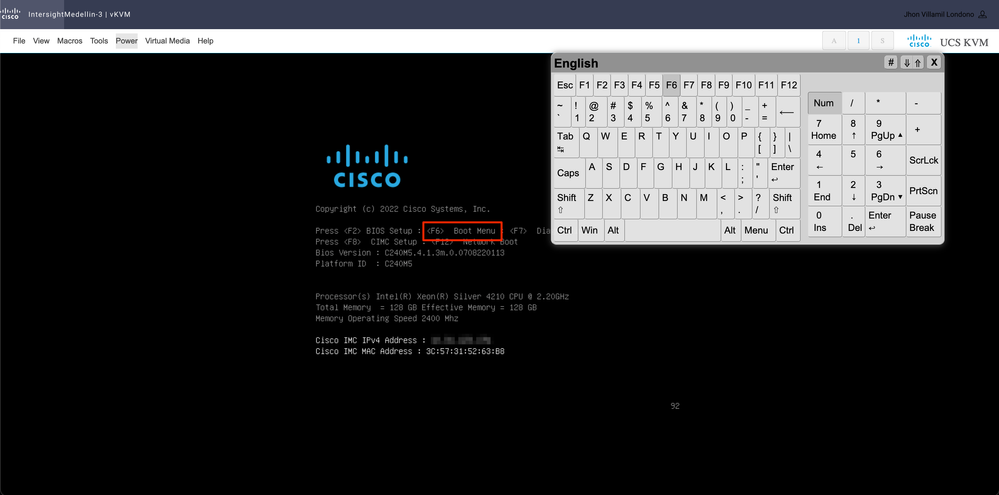
You need to boot into the CD/DVD virtual device device. Navigate to Tools > Select Keyboard > When you see Boot Menu prompt press F6
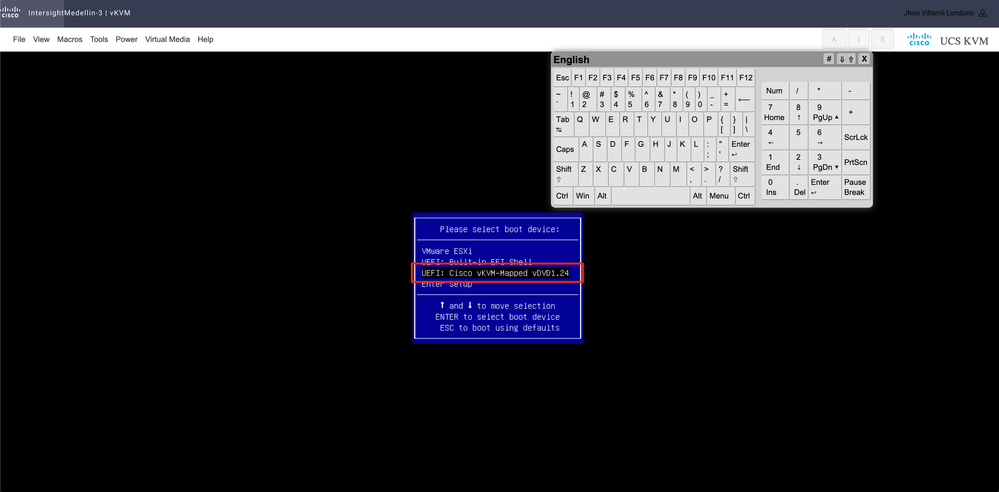
You get to the boot menu and once there select Cisco vKVM-Mapped vDVD1.24 and hit Enter
Select I have read the above notice and wish to continue and hit Enter
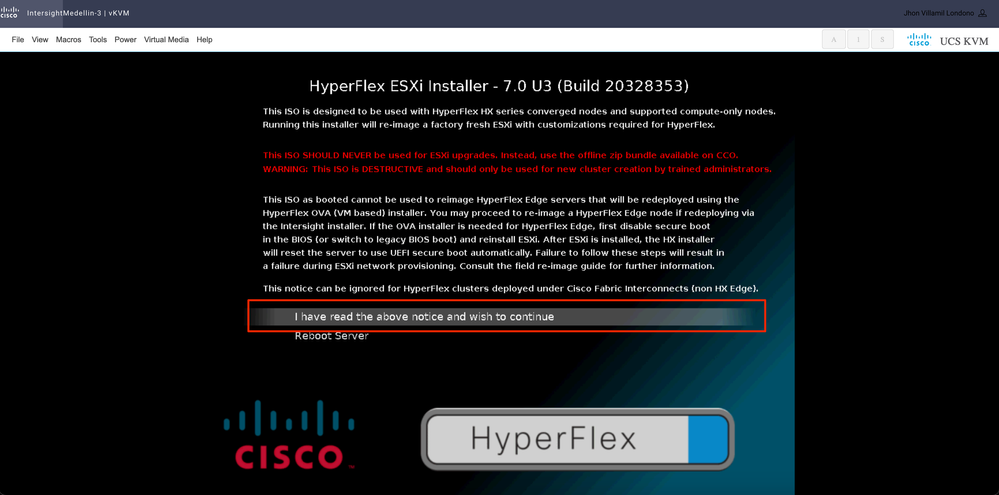
Regularly you see different options for compute nodes depending on what specific boot device is used and another option for converge nodes which is the one you have to select here
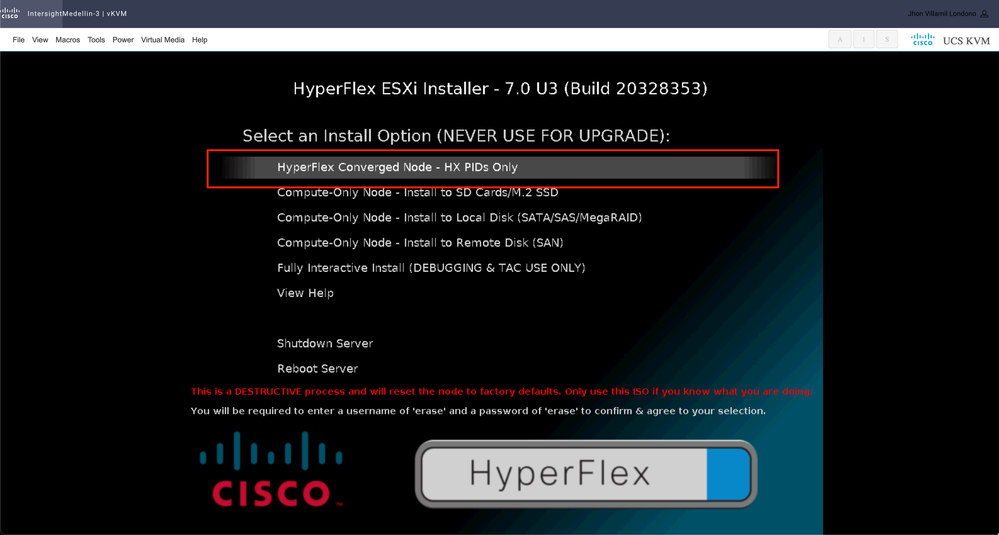
After that you get prompted to enter username and password. Type username erase > hit Enter > Type password erase > hit Enter
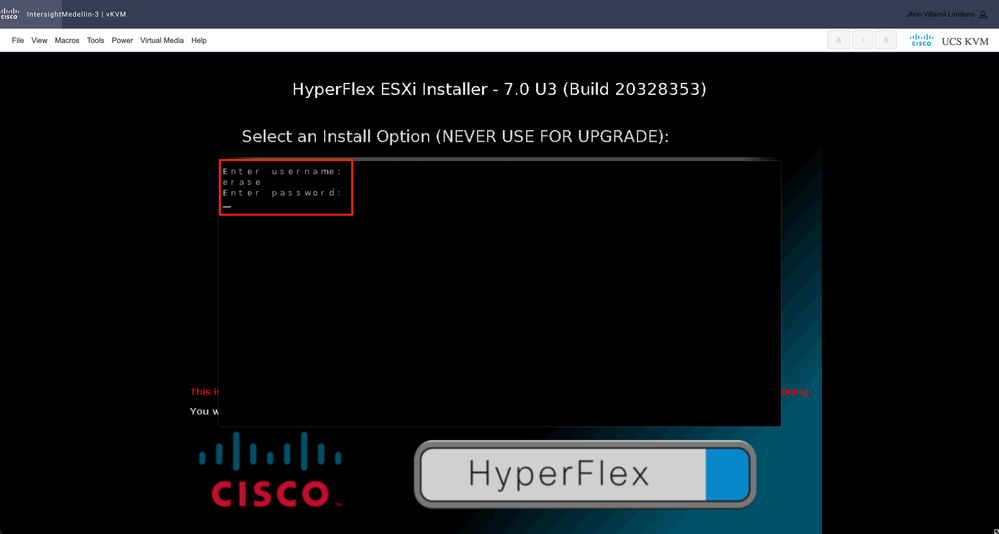
Note: if wrong password/username is entered you are taken back one step and then you are able to try again
Install starts at this point and you are able to monitor it via vKVM
Step 2. Navigate to Infrastructure Service > Hypeflex Clusters > Select your Hyperflex cluster > Select Actions > Select Redeploy Node
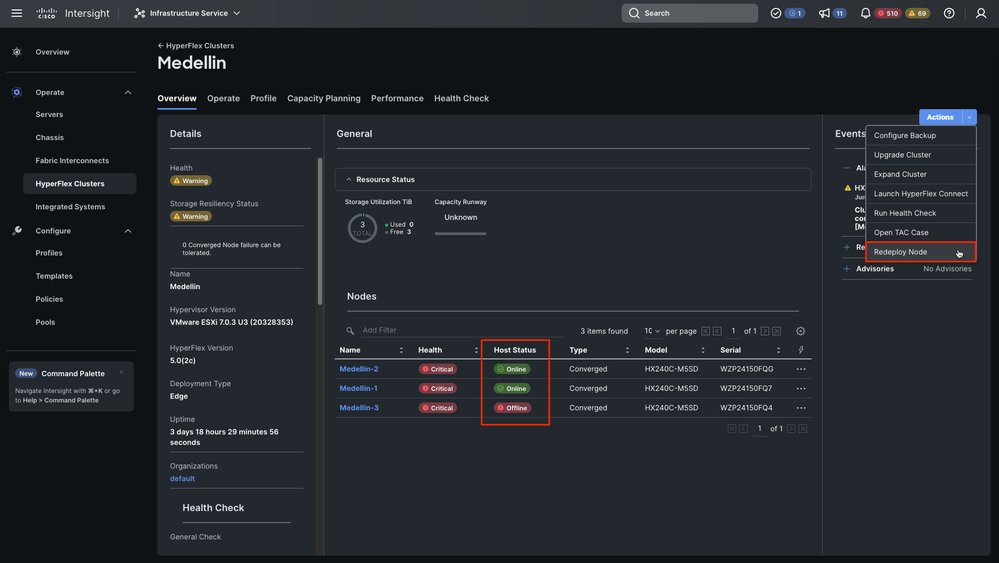

Tip: if only SCVM is corrupted and needs to be reinstalled then you must power-off the server prior to select Redeploy if not you run into error "Redeploy Node cannot be triggered because there are no offline hosts in this cluster."
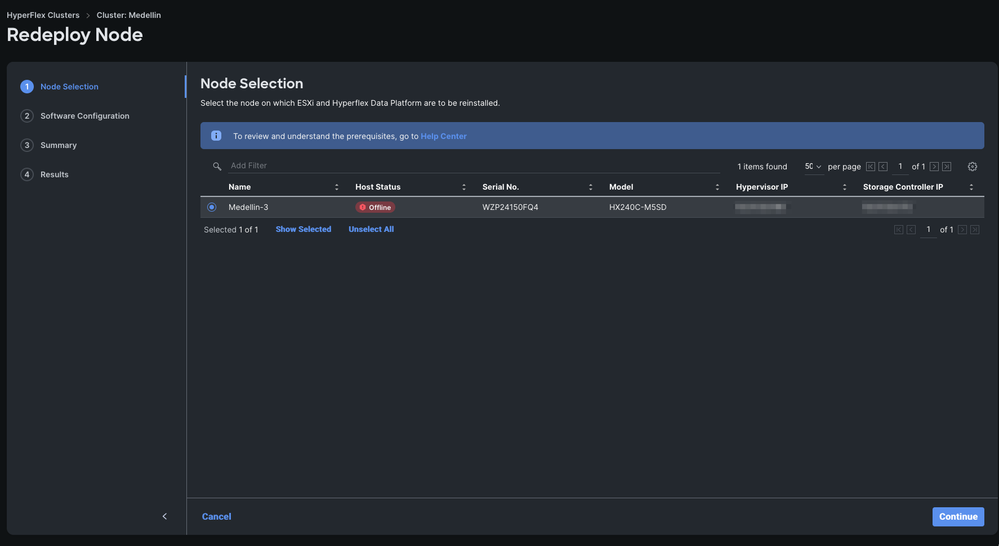
Step 3. Select the node offline > Select Continue
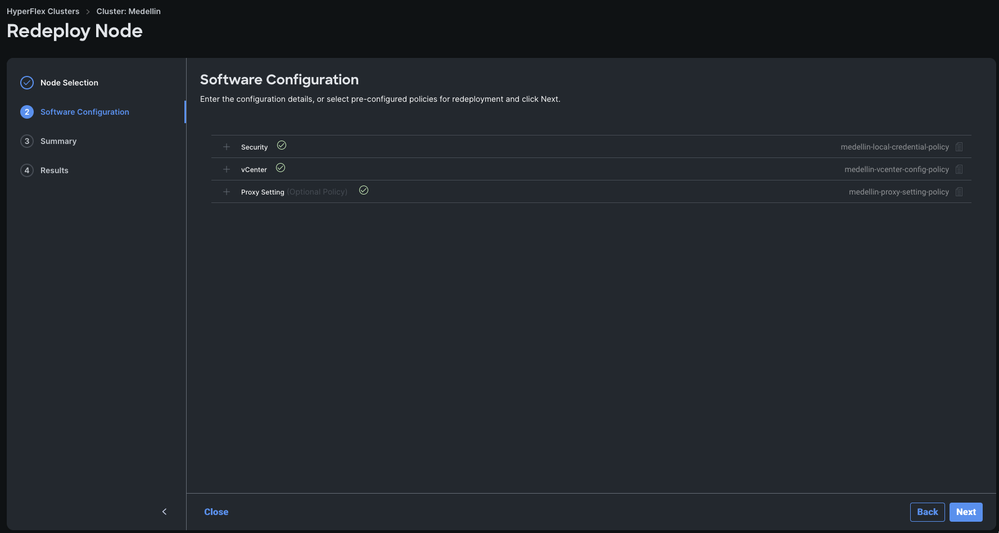
Step 4. Verify Security, vCenter and Proxy Settings policies correspond to the same cluster and select Next
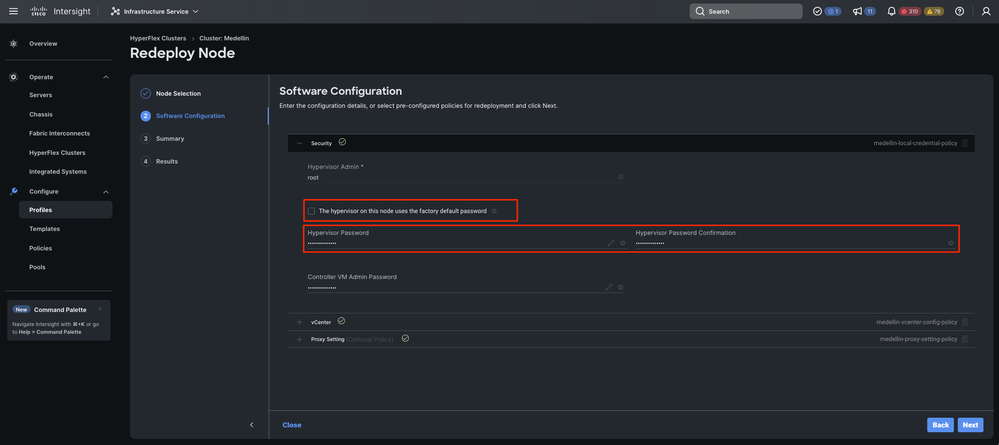
However if only SCVM is being redeployed and ESXi is intact then from the Security Policy you must unselect "The hypervisor on this node uses the factory default password" option and make sure the current ESXi password is updated there before selecting Next
Step 5. Select Validate and Redeploy
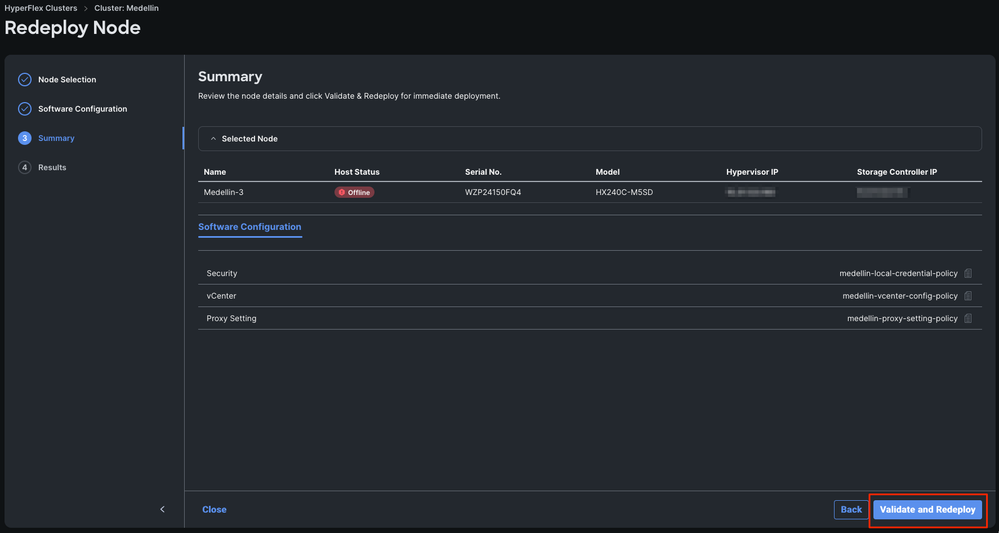
Step 6. Wait for the workflow to complete
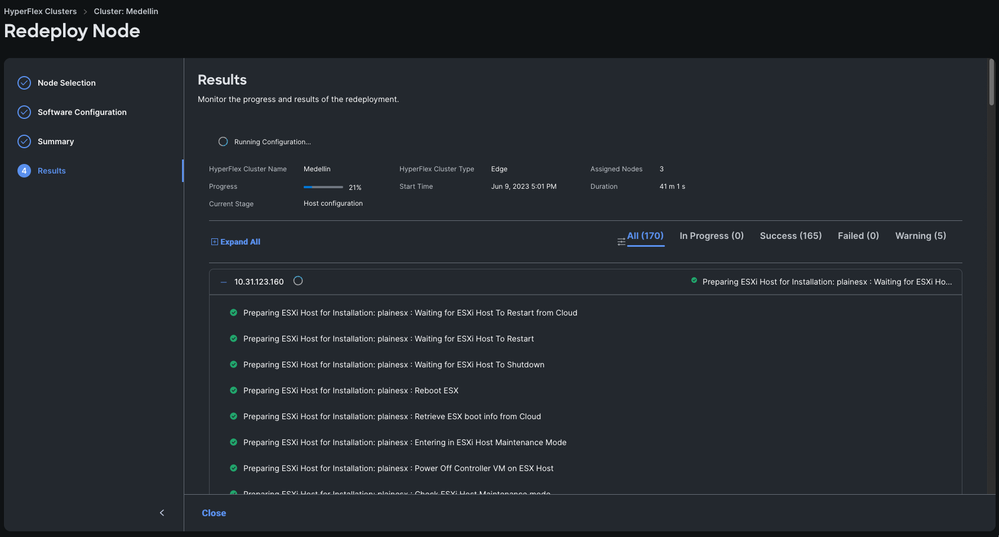
Note: You can monitor the progress but it usually takes few hours
Finally redeploy completed and Medellin cluster is back to healthy status
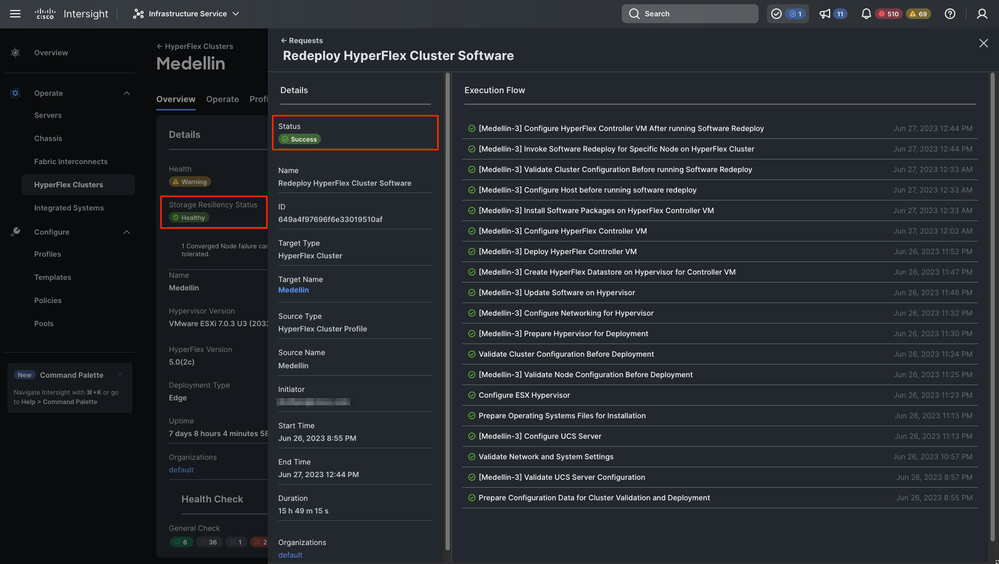
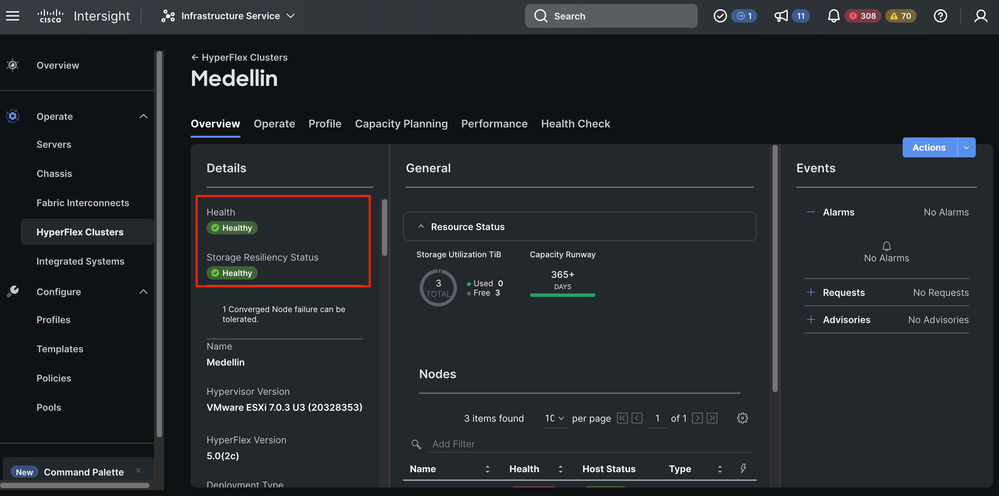
Cluster Healthy Status Validation
Validation from Intersight
Navigate to Hyperflex Clusters > Select the cluster > Select Overview tab
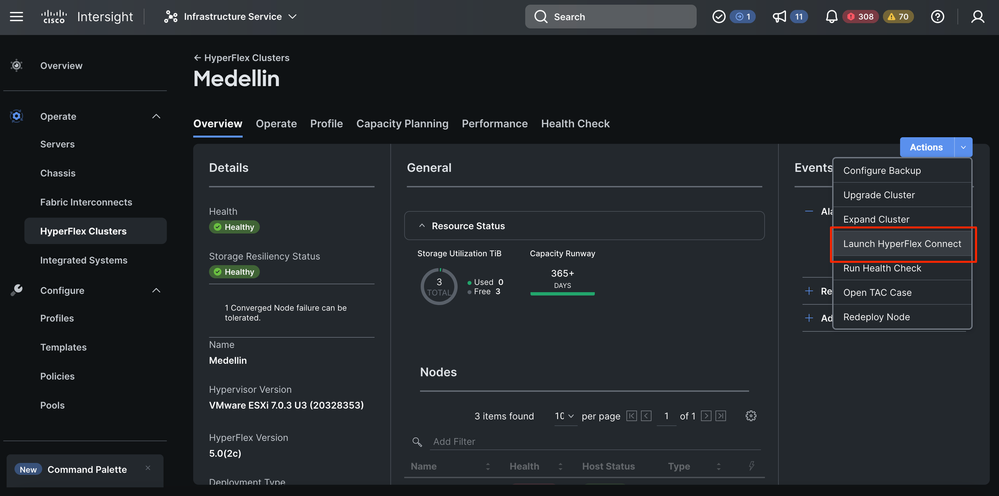
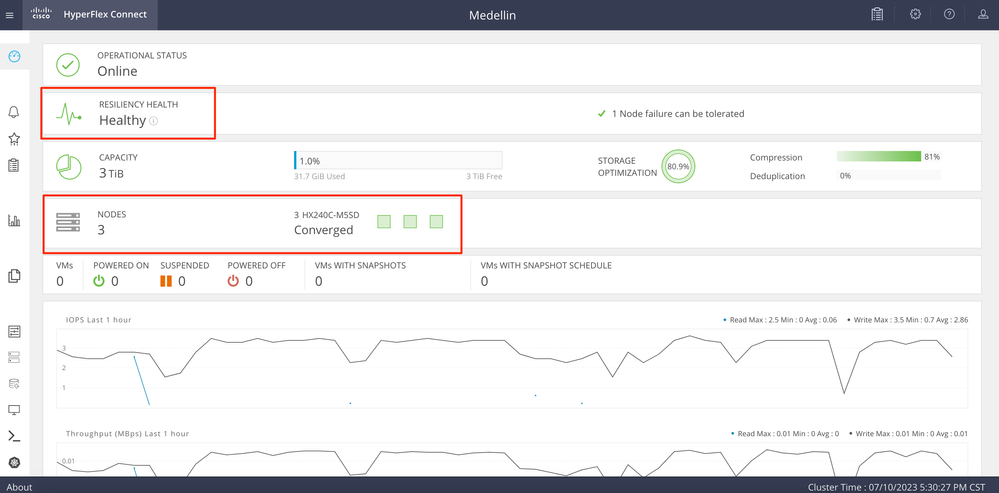
Validation from Hyperflex Connect
Lunch HXDP from Intersight to validate the status from there
Validation from CLI
From CLI you can use commands such as: hxcli cluster status , hxcli cluster info, hxcli cluster health, hxcli node list
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : HEALTHY
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 1
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 31.7 GiB
Free Capacity : 3.0 TiB
Compression Savings : 80.90%
Deduplication Savings : 0.00%
Total Savings : 80.90%
# of Nodes Configured : 3
# of Nodes Online : 3
Data IP Address : 169.254.218.1
Resiliency Health : HEALTHY
Policy Compliance : COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 1
# of persistent device failures tolerable : 2
# of cache device failures tolerable : 2
Zone Type : Unknown
All Flash : No
Related Information
HyperFlex Node Redeployment Workflow
 Feedback
Feedback