Entwerfen von großen Stub-Netzwerken mit ODR
Inhalt
Einführung
On-Demand Routing (ODR) ist eine Erweiterung des Cisco Discovery Protocol (CDP), einem Protokoll zur Erkennung anderer Cisco Geräte auf Broadcast- oder Nicht-Broadcast-Medien. Mithilfe von CDP können Sie den Gerätetyp, die IP-Adresse, die Cisco IOS® Version, die auf dem benachbarten Cisco Gerät ausgeführt wird, die Funktionen des benachbarten Geräts usw. ermitteln. In der Cisco IOS-Softwareversion 11.2 wurde CDP ODR hinzugefügt, um das angeschlossene IP-Präfix eines Stub-Routers über CDP anzukündigen. Diese Funktion benötigt zusätzlich fünf Byte für jedes Netzwerk oder Subnetz, vier Byte für die IP-Adresse und ein Byte, um die Subnetzmaske zusammen mit der IP anzukündigen. ODR kann VLSM-Informationen (Subnetzmaske mit variabler Länge) übertragen.
ODR wurde für Einzelhandelskunden entwickelt, die ihre Netzwerkbandbreite nicht für Routing-Protokoll-Updates verwenden möchten. In einer X.25-Umgebung ist es beispielsweise oft sehr kostspielig, ein Routing-Protokoll über diese Verbindung auszuführen. Statisches Routing ist eine gute Wahl, es gibt jedoch zu viel Overhead, um die statischen Routen manuell zu verwalten. ODR ist nicht CPU-intensiv und wird verwendet, um IP-Routen dynamisch über Layer 2 zu propagieren.
ODR ist kein Routing-Protokoll und sollte bei der Konfiguration nicht als solches behandelt werden. Herkömmliche Konfigurationen für verschiedene IP-Routing-Protokolle funktionieren im ODR nicht, da der ODR CDP auf Layer 2 verwendet. Um den ODR zu konfigurieren, verwenden Sie den Befehl Router odr auf dem Hub-Router. Design, Implementierung und Interaktion von ODR mit anderen IP-Routing-Protokollen können schwierig sein.
ODR wird nicht auf Routern der Cisco 700-Serie oder über ATM-Verbindungen ausgeführt, mit Ausnahme der LAN-Emulation (LAN).
Stub Networks vs. Transit Networks
Wenn keine Informationen das Netzwerk durchlaufen, handelt es sich um ein Stub-Netzwerk. Hub-and-Spoke-Topologie ist ein gutes Beispiel für ein Stub-Netzwerk. Große Unternehmen mit vielen Standorten, die mit einem Rechenzentrum verbunden sind, verwenden diese Topologie.
Auf der Spoke-Seite werden Low-End-Router wie Cisco Router der Serien 2500, 1600 und 1000 eingesetzt. Wenn Informationen über Spoke-Router an ein anderes Netzwerk weitergeleitet werden, wird dieser Stub-Router zum Transit-Router. Diese Konfiguration tritt auf, wenn ein Spoke-Router neben dem Hub-Router mit einem anderen Router verbunden ist.
Ein häufiges Problem ist, wie groß ein ODR-Update sein kann, das ein Spoke senden kann. In der Regel sind Spokes nur mit einem Hub verbunden. Wenn Spokes mit anderen Routern verbunden sind, sind sie keine Stubs mehr und werden zu einem Transit-Netzwerk. Low-End-Boxen verfügen in der Regel über eine oder zwei LAN-Schnittstellen. Beispielsweise kann der Cisco 2500 zwei LAN-Schnittstellen unterstützen. In normalen Situationen wird ein 10-Byte-Paket als Teil des CDP gesendet (falls zwei LANs auf der Spoke-Seite vorhanden sind). CDP ist standardmäßig aktiviert, sodass kein zusätzlicher Overhead entsteht. Es wird nie zu einer Situation kommen, in der es eine große ODR-Aktualisierung gibt. In einer Hub-and-Spoke-Umgebung stellt die Größe der ODR-Updates kein Problem dar.
Hub-and-Spoke-Netzwerke und ODR
Ein Hub-and-Spoke-Netzwerk ist ein typisches Netzwerk, in dem ein Hub (High-End-Router) viele Spokes (Low-End-Router) bedient. In Sonderfällen kann es mehr als einen Hub geben, entweder aus Redundanzgründen oder um zusätzliche Stationen über einen separaten Hub zu unterstützen. Aktivieren Sie in diesem Fall ODR an beiden Hubs. Außerdem ist ein Routing-Protokoll erforderlich, um ODR-Routing-Informationen zwischen den beiden Hubs auszutauschen.
Abbildung 1: Hub-and-Spoke-Topologie 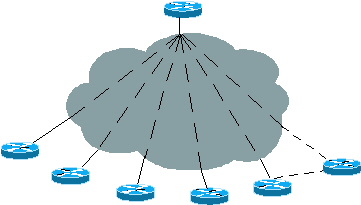
Spokes mit einem einzigen Ausgangspunkt
In Abbildung 1 sind die Stationen mit einem Hub verbunden, sodass sie sich auf das Standard-Gateway verlassen können, anstatt alle Routing-Informationen für den Hub mit einem Ausgangspunkt zu empfangen. Es ist nicht erforderlich, alle Informationen an die Spokes weiterzuleiten, da ein Spoke keine intelligente Routing-Entscheidung treffen muss. Ein Spoke sendet den Datenverkehr immer an den Hub, sodass die Spokes nur eine Standardroute benötigen, die auf einen Hub zeigt.
Die Subnetzinformationen des Spokes müssen an den Hub gesendet werden können. Vor Cisco IOS 11.2 war die einzige Möglichkeit, dies zu erreichen, die Aktivierung eines Routing-Protokolls am Spoke-System. Bei Verwendung von ODR müssen Routing-Protokolle jedoch nicht auf der Spoke-Seite aktiviert werden. Bei ODR werden nur Cisco IOS 11.2 und eine statische Standardroute benötigt, die auf einen Hub zeigt.
Spokes mit mehreren Ausgangspunkten
Ein Spoke kann aus Redundanz- oder Backup-Gründen mehrere Verbindungen zum Hub haben, falls die primäre Verbindung ausfällt. Für diese Redundanz ist häufig ein separater Hub erforderlich. In dieser Situation haben die Stationen mehrere Ausstiegspunkte. ODR funktioniert auch in diesem Netzwerk gut.
Spokes müssen Point-to-Point sein, da andernfalls die Floating-Standardroute nicht funktioniert. In einer Multipoint-Konfiguration ist es nicht möglich, einen Ausfall des nächsten Hop zu erkennen, genau wie bei einem Broadcast-Medium.
Lastenausgleich oder Backup mit einem einzelnen Hub
Um einen Lastenausgleich zu erreichen, definieren Sie zwei statische Standardrouten auf Stationen mit derselben Entfernung. Die Spoke-Route führt einen Lastenausgleich zwischen diesen beiden Pfaden durch. Wenn zwei Pfade zum Ziel vorhanden sind, behält der ODR beide Routen in der Routing-Tabelle bei und führt einen Lastenausgleich auf dem Hub durch.
Definieren Sie für Backups zwei statische Standardrouten mit einer besseren Entfernung als die anderen. Der Spoke-Router verwendet die primäre Verbindung, und wenn die primäre Verbindung ausfällt, funktioniert die Floating-statische Route. Verwenden Sie im Hub-Router den Distanzbefehl für jede CDP-Nachbaradresse, um eine Entfernung besser als die andere zu machen. Bei dieser Konfiguration werden die über eine Verbindung empfangenen ODR-Routen gegenüber der anderen bevorzugt. Diese Konfiguration ist in einer Umgebung nützlich, in der schnelle primäre Links und langsame (niedrige Bandbreite) Backup-Verbindungen vorhanden sind und kein Load Balancing erwünscht ist.
Hinweis: Heute gibt es auf der Spoke-Seite keine andere Methode, eine Verbindung in einer Hub-Situation der anderen vorzuziehen, außer wie oben beschrieben. Wenn Sie IOS 12.0.5T oder höher verwenden, sendet der Hub automatisch die Standardroute über beide Links, und das Spoke kann nicht zwischen den beiden Pfaden unterscheiden und installiert beide Pfade in der Routing-Tabelle. Die einzige Möglichkeit, eine Standard-Route einer anderen vorzuziehen, besteht darin, eine statische Standardroute auf dem Spoke zu verwenden, deren Pfad eine niedrigere Admin-Distanz hat, für die Sie es vorziehen möchten. Dadurch werden automatisch die Standardrouten überschrieben, die über den ODR in den Stationen eintreffen. Derzeit wird die Idee erwogen, den Spoke-a-Knopf, wo es eine Verbindung bevorzugen kann gegenüber der anderen, zu geben.
Abbildung 2: Spots mit mehreren Ausgangspunkten und einem einzigen Hub 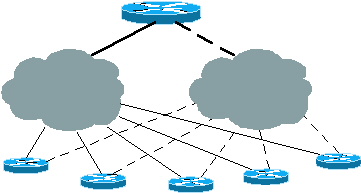
Lastenausgleich oder Backup mit mehreren Hubs
Diese Konfigurationen können auch für Lastenausgleich oder Backups verwendet werden, wenn mehrere Hubs vorhanden sind. Alle Hubs müssen vollständig vermascht sein, damit bei Ausfall einer der Verbindungen von den Stationen das Ziel trotzdem über einen zweiten Hub erreicht werden kann. Ausführlichere Erläuterungen finden Sie im Abschnitt ODR im Vergleich zu anderen Routing-Protokollen dieses Dokuments. Bei mehreren Hubs, wenn IOS 12.0.5T oder höher verwendet wird, senden die Hubs die ODR-Standardrouten an Stationen und Stationen, die beide in der Routing-Tabelle installieren. Eine zukünftige Erweiterung ermöglicht es einem Spoke, einen Hub dem anderen vorzuziehen. Derzeit kann dies über eine statische Standardroute erfolgen, die auf dem Router des Spokes definiert ist, und über die Admin-Distanz im Befehl für die statische Route kann der eine Hub dem anderen vorgezogen werden. Dies betrifft keine Load Balancing-Situationen.
Abbildung 3: Spots mit mehreren Ausgangspunkten und mehreren Hubs 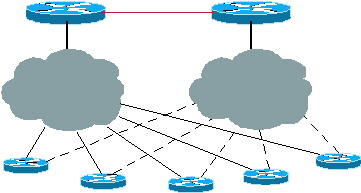
ODR im Vergleich zu anderen Routing-Protokollen
Der größte Vorteil von ODR-over-IP-Routing besteht darin, dass der Hub-Router IP-Präfixe erkennt, ohne Routing-Protokolle auf Layer 3 zu aktivieren. Die ODR-Updates sind Teil von CDP auf Layer 2.
ODR im Vergleich zu EIGRP
In einer Hub-and-Spoke-Umgebung ist es nicht erforderlich, alle Routing-Informationen an alle Spokes weiterzuleiten. Eine langsame Verbindung verschwendet Bandbreite in Routing-Updates und der Aufrechterhaltung von Beziehungen zu Nachbarn. Durch Aktivieren des Enhanced Interior Gateway Routing Protocol (EIGRP) auf den Stationen werden Routing-Updates an die Stationen gesendet. In großen Netzwerken werden diese Updates zu umfangreich, verschwenden die CPU-Bandbreite und erfordern möglicherweise mehr Speicher auf Spoke-Routern.
Ein besserer Ansatz bei EIGRP ist die Anwendung von Filtern am Hub. Die Routing-Informationen werden so gesteuert, dass Hubs nur eine Standardroute dynamisch an die Stationen senden. Diese Filter reduzieren die Größe der Routing-Tabelle auf der Spoke-Seite. Wenn der Hub jedoch einen Nachbarn verliert, sendet er Abfragen an alle anderen Nachbarn. Diese Abfragen sind nicht erforderlich, da der Hub nie eine Antwort von einem Nachbarn erhält.
Der beste Ansatz besteht darin, den Overhead von EIGRP-Anfragen und Nachbar-Wartung mithilfe von ODR zu eliminieren. Durch die Anpassung der ODR-Timer kann die Konvergenzzeit erhöht werden.
Heute haben wir eine neue Funktion in EIGRP, die EIGRP in einer Hub-and-Spoke-Situation wesentlich besser skalieren kann. Weitere Informationen zur EIGRP-Stub-Funktion finden Sie unter Enhanced IGRP Stub Routing.
ODR und OSPF
Open Shortest Path First (OSPF) bietet mehrere Optionen für Hub-and-Spoke-Umgebungen, und die Option Stub no-summary bietet den geringsten Overhead.
Bei der Ausführung von OSPF in großen Hub-and-Spoke-Netzwerken können Probleme auftreten. In den Beispielen in diesem Abschnitt wird Frame Relay verwendet, da es sich um die häufigste Hub-and-Spoke-Topologie handelt.
OSPF Point-to-Point Stub-Netzwerke
In diesem Beispiel ist OSPF auf 100 Spokes aktiviert, die durch eine Point-to-Point-Konfiguration verbunden sind. Zunächst gibt es eine Menge verschwendete IP-Adressen, selbst wenn wir Subnetz mit einer /30-Netzwerkmaske. Zweitens: Wenn wir diese 100 Spokes in einem Bereich einbeziehen und ein Spoke-Verfahren angekreuzt ist, wird der SPF-Algorithmus (Shortest Path First) ausgeführt und kann CPU-intensiv werden. Diese Situation gilt insbesondere für Spoke-Router, wenn die Verbindung ständig blinkt. Eine größere Anzahl von Nachbar-Flaps kann bei Spoke-Routern zu Problemen führen.
In OSPF ist der Bereich Stub und nicht die Schnittstelle. Wenn sich in einem Stub-Netzwerk 100 Router befinden, ist mehr Speicher auf den Stationen erforderlich, um die große Datenbank zu speichern. Dieses Problem kann gelöst werden, indem man einen großen Stub in kleine Bereiche teilt. Eine Klappe in einem Stub-Bereich löst jedoch immer noch den SPF-Betrieb auf den Stationen aus, sodass dieser Overhead nicht geheilt werden kann, indem ein kleiner Stub-Bereich ohne Zusammenfassung und ohne externe Effekte erstellt wird.
Eine weitere Option besteht darin, jeden Link in einen Bereich einzubinden. Bei dieser Option muss der Hub-Router für jeden Bereich einen separaten SPF-Algorithmus ausführen und eine Zusammenfassung der LSAs (Link-State Advertisement) für Routen in diesem Bereich erstellen. Diese Option kann die Leistung des Hub-Routers beeinträchtigen.
Ein Upgrade auf eine bessere Plattform ist keine dauerhafte Lösung. ODR bietet jedoch eine Lösung. Über ODR abgefragte Routen können in OSPF neu verteilt werden, um andere Hub-Router über diese Routen zu informieren.
OSPF Point-to-Multipoint Stub-Netzwerke
In Point-to-Multipoint-Netzwerken wird der IP-Adressraum gespeichert, indem jede Spoke-Nachricht im gleichen Subnetz gespeichert wird. Außerdem wird die Größe des generierten LSA-Hubs des Routers halbiert, da für alle Point-to-Point-Verbindungen nur ein Stub-Link generiert wird. Bei einem Point-to-Multipoint-Netzwerk muss das gesamte Subnetz in einen Bereich integriert werden. Bei einer Verbindungs-Klappe wird SPF ausgeführt, was CPU-intensiv sein kann.
Der Hello Storm
OSPF-Hello-Pakete sind klein, aber wenn es zu viele Nachbarn gibt, kann ihre Größe groß werden. Da die Hellos Multicast sind, verarbeitet der Router die Pakete. Der OSPF-Hub sendet und empfängt Hello-Pakete, die aus 20 Byte IP-Header, 24 Byte OSPF-Header, 20 Byte Hello-Parameter und 4 Byte für jeden erkannten Nachbarn bestehen. Ein OSPF-Hello-Paket von einem Hub in einem Point-to-Multipoint-Netzwerk mit 100 Nachbarn kann 464 Byte lang werden und wird alle 30 Sekunden an alle Spokes überflutet.
Tabelle 1: OSPF Hello-Paket für 100 Nachbarn| IP-Header mit 20 Byte |
| 24 Byte OSPF-Header |
| 20 Byte Hello-Parameter |
| 4 Byte pro Nachbarrouter-ID (RID) |
| . . . |
| . . . |
| . . . |
| . . . |
| . . . |
Der Overhead wird im ODR aufgelöst, da keine zusätzlichen Informationen vom Hub an die Stationen gesendet werden. Die Stationen senden das IP-Präfix von 5 Byte pro Subnetz an den Hub-Router. Wenn man die Größe des Hello-Pakets berücksichtigt, vergleichen Sie die 5 Byte im ODR (die Spoke-Senderinformationen eines angeschlossenen Subnetzes) mit den 68 Byte OSPF (die kleinste Hello-Paketgröße einschließlich eines vom Spoke-Hub an den Hub gesendeten IP-Headers) plus 68 Byte (das kleinste Hello-Paket, das vom Hub an den Spoke gesendet wird) in einem 30-Intervall. Die OSPF-Hellos treten auch auf Layer 3 auf, während die ODR-Updates auf Layer 2 erfolgen. Mit ODR werden weitaus weniger Informationen gesendet, sodass die Verbindungsbandbreite für wichtige Daten verwendet werden kann.
ODR im Vergleich zu RIPv2
Routing Information Protocol Version 2 (RIPv2) eignet sich auch für Hub-and-Spoke-Umgebungen. Um RIPv2 zu entwerfen, senden Sie die Standardroute vom Hub an die Stationen. Die Spokes geben dann ihre verbundene Schnittstelle über RIP an. RIPv2 kann verwendet werden, wenn sekundäre Adressen auf den Spokes angezeigt werden müssen, wenn mehrere Router eines Anbieters verwendet werden oder wenn die Situation nicht wirklich ein Hub and Spoke ist.
RIPv2 Over Demand Circuit
Version 2 enthält einige Änderungen, ändert aber das Protokoll nicht drastisch. In diesem Abschnitt werden einige Verbesserungen für RIP für Nachfragemissionen beschrieben.
Die heutigen Internetworks bewegen sich in Richtung DFÜ-Netzwerke oder Backups von primären Standorten, um Verbindungen zu einer großen Anzahl von Remote-Standorten bereitzustellen. Diese Verbindungstypen leiten im normalen Betrieb entweder nur sehr wenig oder gar keinen Datenverkehr weiter.
Das periodische Verhalten von RIP verursacht Probleme auf diesen Schaltkreisen. RIP hat Probleme mit Point-to-Point-Schnittstellen mit geringer Bandbreite. Updates werden alle 30 Sekunden mit großen Routing-Tabellen gesendet, die eine hohe Bandbreite nutzen. In diesem Fall empfiehlt es sich, Triggered RIP (Getriggertes RIP) zu verwenden.
Ausgelöster RIP
Ausgelöstes RIP ist für Router konzipiert, die alle Routing-Informationen mit ihrem Nachbarn austauschen. Wenn Änderungen am Routing vorgenommen werden, werden nur die Änderungen an den Nachbarn weitergeleitet. Der empfangende Router wendet die Änderungen sofort an.
Ausgelöste RIP-Updates werden nur gesendet, wenn:
-
Es wird eine Anforderung für ein Routing-Update empfangen.
-
Es werden neue Informationen empfangen.
-
Das Ziel hat sich von einem Schaltkreis zum nächsten geändert.
-
Der Router ist zuerst eingeschaltet.
Das nachfolgende Beispiel zeigt eine Konfiguration für Triggered RIP:
Spoke# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
Spoke(config)# int s0.1
Spoke(config-if)# ip rip triggered
Spoke(config)# int s0.2
Spoke(config-if)# ip rip triggered
interface serial 0
encapsulation frame-relay
interface serial 0.1 point /* Primary PVC */
ip address 10.x.x.x 255.255.255.0
ip rip triggered
frame-relay interface-dlci XX
interface serial 0.2 point /* Secondary PVC */
ip address 10.y.y.y 255.255.255.0
ip rip triggered
frame-relay interface-dlci XX
router rip
network 10.0.0.0
Spoke# show ip protocol
Routing Protocol is "rip"
Sending updates every 30 seconds, next due in 23 seconds
Invalid after 180 seconds, hold down 180, flushed after 240
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Redistributing: rip
Default version control: send version 1, receive any version
Interface Send Recv Triggered RIP Key-chain
Ethernet0 1 1 2
Serial0.1 1 1 2 Yes
Serial0.2 1 1 2 Yes
Routing for Networks:
10.0.0.0
Routing Information Sources:
Gateway Distance Last Update
Distance: (default is 120)
Der Befehl ip rip trigger muss auf der Schnittstelle des Hub-Routers konfiguriert werden, die mit den Stationen verbunden ist.
Beim Vergleich von RIPv2 mit ODR ist ODR besser geeignet, da RIPv2 auf Layer 3 funktioniert und ODR auf Layer 2 stattfindet. Wenn der Hub RIPv2-Updates an mehr als 1000 Spokes sendet, muss er das Paket auf Layer 3 für jeden Spoke replizieren. ODR sendet jede Minute nichts vom Hub, außer dem üblichen CDP-Update auf Layer 2, das überhaupt nicht CPU-intensiv ist. Das Senden angeschlossener Subnetzinformationen in Layer 2 vom Spoke ist weitaus weniger CPU-intensiv als das Senden von RIPv2 auf Layer 3.
Großes Netzwerkdesign mit ODR
ODR funktioniert in einem großen Netzwerk besser als jedes andere Routing-Protokoll. Der größte Vorteil von ODR besteht darin, dass Routing-Protokolle auf den angeschlossenen seriellen Verbindungen nicht aktiviert werden müssen. Derzeit sind keine Routing-Protokolle in der Lage, Routing-Informationen zu senden, ohne diese über die verbundene Schnittstelle zu aktivieren.
ODR mit EIGRP auf Hubs
Wenn EIGRP ausgeführt wird, stellen Sie eine passive Schnittstellenverbindung zum Hub-and-Spoke-Netzwerk her, sodass die unnötigen EIGRP-Hellos an die Verbindung nicht gesendet werden. Wenn möglich, sollten Sie keine Netzwerkanweisungen für Netzwerke zwischen dem Hub und den Spokes setzen, da EIGRP bei einem Ausfall der Verbindung keine unnötigen Abfragen an die Core-Nachbarn sendet. Wählen Sie zwischen Hub und Spokes immer ein Scheinnetzwerk aus, sodass diese Verbindungen nicht in die EIGRP-Domäne aufgenommen werden, da Sie keine Netzwerkanweisungen in die Konfigurationen einfügen.
Redundanz und Zusammenfassung
In einer Hub-Situation sind keine zusätzlichen Einstellungen erforderlich. Fassen Sie die spezifischen, vernetzten Subnetze der Stationen zusammen und lassen Sie sie in den Kern. Der Aufwand für Anfragen wird jedoch immer da sein. Wenn bestimmte Routen von einer der Spokes verloren gehen, senden Sie die Anfragen an alle Nachbarn der Core-Router.
Bei mehreren Hubs ist es sehr wichtig, dass beide Hubs miteinander verbunden sind und dass EIGRP zwischen den Hubs läuft. Wenn möglich, sollte diese Verbindung ein eindeutiges Hauptnetz sein, damit sie andere Links, die zu den Stationen führen, nicht stört. Diese Konfiguration ist erforderlich, da EIGRP auf einer bestimmten Schnittstelle nicht aktiviert werden kann. Selbst wenn wir die Schnittstelle passiv machen, wird sie dennoch über EIGRP angekündigt. Wenn die Schnittstelle zusammengefasst ist, werden Abfragen trotzdem gesendet, wenn ein Spoke verloren geht. Solange sich die Verbindung zwischen den beiden Hubs nicht im gleichen Hauptnetz wie die Stationen befindet, sollte die Konfiguration ordnungsgemäß funktionieren.
Abbildung 4: Redundanz und Zusammenfassung: Der Core empfängt zusammengefasste Routen. 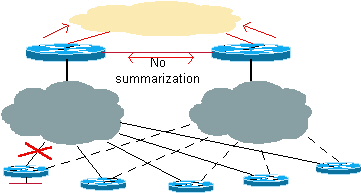
Ein Vorteil von EIGRP besteht darin, dass es auf Schnittstellenebene zusammengefasst werden kann, sodass die zusammengefasste Route von Spoke-Subnetzen an den Kern gesendet wird und eine spezifischere Route an den anderen Hub gesendet wird. Wenn die Verbindung zwischen Hub und Spoke ausfällt, ist es möglich, das Ziel über den zweiten Hub zu erreichen.
ODR mit OSPF auf Hubs
In diesem Szenario muss OSPF nicht auf der Verbindung aktiviert werden, die die Stationen verbindet. Wenn OSPF für die Verbindung aktiviert ist und eine bestimmte Verbindung ständig flackert, kann dies in einem normalen Szenario mehrere Probleme verursachen, darunter die Ausführung des SPF, die LSA-Regeneration des Routers, die zusammengefasste LSA-Wiederherstellung usw. Schließen Sie bei der Ausführung von ODR die angeschlossene serielle Verbindung nicht in die OSPF-Domäne ein. Das Hauptanliegen besteht darin, Informationen über das LAN-Segment der Stationen zu erhalten. Diese Informationen können über ODR abgerufen werden. Wenn eine Verbindung permanent flattert, wird das Routing-Protokoll im Hub-Router nicht beeinträchtigt.
Redundanz und Zusammenfassung
Alle spezifischen Verbindungen können zusammengefasst werden, bevor sie in den Kern gelangen, um eine Routenberechnung zu vermeiden, wenn eine der verbundenen Schnittstellen eines Spokes ausfällt. Sie kann nicht erkannt werden, wenn die Informationen des Core-Routers zusammengefasst sind.
Abbildung 5: Redundanz und Zusammenfassung: Der Core-Router empfängt zusammengefasste Routen. 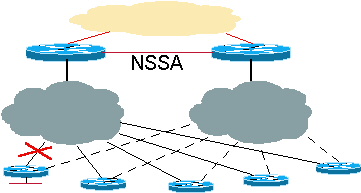
In diesem Beispiel ist es sehr wichtig, dass die Hubs aus Redundanzgründen miteinander verbunden werden. Diese Verbindung fasst auch die mit dem Spoke verbundenen Subnetze zusammen, bevor sie in den OSPF-Core gelangen.
NSSA mit zukünftiger Erweiterung
Es wird irgendwann eine Funktion für OSPF Not-So-Stubby Areas (NSSA) geben, die nicht nur eine Zusammenfassung in den Core, sondern auch spezifischere Informationen über den Hub durch die NSSA-Verbindung ermöglicht. Der Vorteil bei der Ausführung von NSSA besteht darin, dass die zusammengefassten Routen in den Core gesendet werden können. Anschließend kann der Core den Datenverkehr an einen der beiden Hubs senden, um das Ziel des Spokes zu erreichen. Wenn die Verbindung zwischen einem Hub und einem Spoke ausfällt, wird an beiden Hubs ein spezifischerer Typ-7-LSA vorhanden sein, um das Ziel über einen anderen Hub zu erreichen.
Das nachfolgende Beispiel zeigt eine Konfiguration mit NSSA:
N2507: Hub 1
router odr
timers basic 8 24 0 1
!
router ospf 1
redistribute odr subnets
network 1.0.0.0 0.255.255.255 area 1
area 1 nssa
N2504: Hub 2
router odr
timers basic 8 24 0 1
!
router ospf 1
redistribute odr subnets
network 1.0.0.0 0.255.255.255 area 1
area 1 nssa
N2507# show ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, * - candidate default
U - per-user static route, o - ODR
Gateway of last resort is not set
C 1.0.0.0/8 is directly connected, Serial0
C 2.0.0.0/8 is directly connected, Serial1
3.0.0.0/24 is subnetted, 1 subnets
C 3.3.3.0 is directly connected, Ethernet0
o 150.0.0.0/16 [160/1] via 3.3.3.2, 00:00:23, Ethernet0
o 200.1.1.0/24 [160/1] via 3.3.3.2, 00:00:23, Ethernet0
o 200.1.2.0/24 [160/1] via 3.3.3.2, 00:00:23, Ethernet0
N2504# show ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, * - candidate default
U - per-user static route, o - ODR
Gateway of last resort is not set
C 1.0.0.0/8 is directly connected, Serial0
C 2.0.0.0/8 is directly connected, Serial1
3.0.0.0/24 is subnetted, 1 subnets
C 3.3.4.0 is directly connected, TokenRing0
C 5.0.0.0/8 is directly connected, Loopback0
C 6.0.0.0/8 is directly connected, Loopback1
O N2 150.0.0.0/16 [110/20] via 1.0.0.1, 00:12:06, Serial0
O N2 200.1.1.0/24 [110/20] via 1.0.0.1, 00:12:06, Serial0
O N2 200.1.2.0/24 [110/20] via 1.0.0.1, 00:12:06, Serial0
Zusammenfassung und künftige Optimierung mit NSSA
Weisen Sie den Stationen einen zusammenhängenden Block von Subnetzen zu, sodass diese Subnetze korrekt im OSPF-Core zusammengefasst werden können (siehe folgendes Beispiel). Wenn die Subnetze nicht zusammengefasst sind und ein angeschlossenes Subnetz ausfällt, wird es vom gesamten Core erkannt und die Routen neu berechnet. Wenn die zusammengefasste Route für einen zusammenhängenden Block gesendet wird, erkennt der Core sie nicht, wenn das Spoke-Subnetz-Flaps erkennt.
N2504# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
N2504(config)# router ospf 1
N2504(config-router)# summary-address 200.1.0.0 255.255.0.0
N2504# show ip ospf database external
OSPF Router with ID (6.0.0.1) (Process ID 1)
Type-5 AS External Link States
LS age: 1111
Options: (No TOS-capability, DC)
LS Type: AS External Link
Link State ID: 200.1.0.0 (External Network Number )
Advertising Router: 6.0.0.1
LS Seq Number: 80000001
Checksum: 0x2143
Length: 36
Network Mask: /16
Metric Type: 2 (Larger than any link state path)
TOS: 127
Metric: 16777215
Forward Address: 0.0.0.0
External Route Tag: 0
Distanzproblem
In diesem Beispiel erhalten beide Hubs genauere Informationen. Da die OSPF-Entfernung 110 beträgt und die ODR-Entfernung 160 beträgt, stören die Informationen die ODR, wenn sie vom anderen Hub über dasselbe Subnetz empfangen werden. Der andere Hub wird immer bevorzugt, um an das Spoke-Ziel zu gelangen, was zu suboptimalem Routing führt. Um Abhilfe zu schaffen, sollte die ODR-Entfernung mit dem Distanzbefehl auf weniger als 110 reduziert werden, sodass die ODR-Route immer der OSPF-Route vorgezogen wird. Wenn die ODR-Route fehlschlägt, wird die externe OSPF-Route in der Routing-Tabelle aus der Datenbank installiert.
N2504(config)# router odr
N2504(config-router)# distance 100
N2504(config-router)# end
N2504# show ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, * - candidate default
U - per-user static route, o - ODR
Gateway of last resort is not set
C 1.0.0.0/8 is directly connected, Serial0
C 2.0.0.0/8 is directly connected, Serial1
3.0.0.0/24 is subnetted, 1 subnets
C 3.3.4.0 is directly connected, TokenRing0
C 5.0.0.0/8 is directly connected, Loopback0
C 6.0.0.0/8 is directly connected, Loopback1
o 150.0.0.0/16 [100/1] via 3.3.4.1, 00:00:39, TokenRing0
o 200.1.1.0/24 [100/1] via 3.3.4.1, 00:00:39, TokenRing0
o 200.1.2.0/24 [100/1] via 3.3.4.1, 00:00:39, TokenRing0
O 200.1.0.0/16 is a summary, 00:04:38, Null0
Die N2-Routen befinden sich weiterhin in der Datenbank und werden aktiv, wenn die Haupt-Hub-Verbindung zum Spoke ausfällt.
N2504# show ip ospf database nssa
OSPF Router with ID (6.0.0.1) (Process ID 1)
Type-7 AS External Link States (Area 1)
LS age: 7
Options: (No TOS-capability, Type 7/5 translation, DC)
LS Type: AS External Link
Link State ID: 150.0.0.0 (External Network Number )
Advertising Router: 6.0.0.1
LS Seq Number: 80000002
Checksum: 0x965E
Length: 36
Network Mask: /16
Metric Type: 2 (Larger than any link state path)
TOS: 0
Metric: 20
Forward Address: 1.0.0.2
External Route Tag: 0
Durch die Erweiterung auf NSSA befindet sich das spezifischere LSA vom Typ 7 in der NSSA-Datenbank. Anstelle einer zusammengefassten Route wird die Ausgabe der NSSA-Datenbank wie folgt angezeigt:
LS age: 868
Options: (No TOS-capability, Type 7/5 translation, DC)
LS Type: AS External Link
Link State ID: 200.1.1.0 (External Network Number)
Advertising Router: 3.3.3.1
LS Seq Number: 80000001
Checksum: 0xDFE0
Length: 36
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
TOS: 0
Metric: 20
Forward Address: 1.0.0.1
External Route Tag: 0
LS age: 9
Options: (No TOS-capability, Type 7/5 translation, DC)
LS Type: AS External Link
Link State ID: 200.1.2.0 (External Network Number)
Advertising Router: 3.3.3.1
LS Seq Number: 80000002
Checksum: 0xFDC3
Length: 36
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
TOS: 0
Metric: 20
Forward Address: 1.0.0.2
External Route Tag: 0
Nachfragesteuerung
Der Demand Circuit ist eine Cisco IOS 11.2-Funktion, die auch in Hub-and-Spoke-Netzwerken verwendet werden kann. Diese Funktion ist in der Regel in Dial-Backup-Szenarien und in X.25- oder Frame Relay Switched Virtual Circuit (SVC)-Umgebungen nützlich. Das nachfolgende Beispiel zeigt eine Konfiguration für einen Lastkreis:
router ospf 1
network 1.1.1.0 0.0.0.255 area 1
area 1 stub no-summary
interface Serial0 /* Link to the hub router */
ip address 1.1.1.1 255.255.255.0
ip ospf demand-circuit
clockrate 56000
Spoke#show ip o int s0
Serial0 is up, line protocol is up
Internet Address 1.1.1.1/24, Area 1
Process ID 1, Router ID 141.108.4.2, Network Type POINT_TO_POINT, Cost: 64
Configured as demand circuit.
Run as demand circuit.
DoNotAge LSA not allowed (Number of DCbitless LSA is 1).
Transmit Delay is 1 sec, State POINT_TO_POINT,
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
Hello due in 00:00:06
Neighbor Count is 1, Adjacent neighbor count is 1
Adjacent with neighbor 130.2.4.2
Suppress hello for 0 neighbor(s)
Wenn die Funktion für die Laststromführung in einem Hub-and-Spoke-Netzwerk verwendet wird, wird der Stromkreis aktiviert und eine neue Adjazenz aufgebaut, wenn sich die Topologie ändert. Wenn z. B. ein Subnetz in einem Spoke vorhanden ist, das einen Flapping auslöst, wird die Adjacency aufgerufen und diese Informationen überflutet. In einer Stubby-Area-Umgebung werden diese Informationen im Stub-Bereich überflutet. ODR löst dieses Problem, indem es diese Informationen nicht an die anderen Stationen weiterleitet. Weitere Informationen finden Sie unter OSPF Demand Circuit Feature.
ODR mit Point-to-Point-Netzwerken
Der aktuelle Cisco IOS 12.0-Status bei IDB (Interface Descriptor Block) ist wie folgt:
| Router | Begrenzung |
|---|---|
| 1000 | 300 |
| 2600 | 300 |
| 3600 | 600 |
| 4 x 00 | 300 |
| 5200 | 300 |
| 5300 | 700 |
| 5800 | 3000 |
| 7200 | 3000 |
| RSP | 1000 |
Vor IOS 12.0 lag die maximale Anzahl der Spokes, die ein Hub unterstützen konnte, aufgrund von IDB-Beschränkungen bei 300. Wenn für ein Netzwerk mehr als 300 Spokes erforderlich waren, war die Point-to-Point-Konfiguration keine gute Wahl. Außerdem wurde für jede Verbindung ein separates CDP-Paket generiert. Die Zeitkomplexität für das Senden von CDP-Updates über Point-to-Point-Verbindungen beträgt n2. Die obige Tabelle enthält die IDB-Grenzwerte für verschiedene Plattformen. Die maximale Anzahl an Spokes, die auf jeder Plattform unterstützt werden, ist unterschiedlich, aber der Aufwand, ein separates CDP-Paket für jede Verbindung zu erstellen, ist weiterhin ein Problem. In einer großen Hub-and-Spoke-Situation ist die Konfiguration einer Point-to-Multipoint-Schnittstelle daher eine bessere Lösung als eine Point-to-Point-Schnittstelle.
ODR mit Point-to-Multipoint Networks
In einem Point-to-Multipoint-Netzwerk, in dem ein Hub mehrere Spokes unterstützt, gibt es drei Hauptprobleme:
-
Der Hub unterstützt problemlos mehr als 300 Spokes. Beispielsweise kann ein 10.10.0.0/22-Netzwerk 1024-2-Stationen mit einer Multipoint-Schnittstelle unterstützen.
-
In einer Multipoint-Umgebung wird für alle Nachbarn ein CDP-Paket generiert und auf Layer 2 repliziert. Die zeitliche Komplexität des CDP-Updates wird auf n reduziert.
-
In einer Point-to-Multipoint-Konfiguration können Sie allen Stationen nur ein Subnetz zuweisen.
ODR und mehrere Anbieter
Ein häufiges Missverständnis besteht darin, dass ODR nicht funktioniert, wenn mehrere Anbieter eingesetzt werden. ODR funktioniert, solange das Netzwerk ein echtes Hub-and-Spoke-Netzwerk ist. Wenn es z. B. 100 Spokes gibt und zwei der Spokes Router eines anderen Anbieters sind, ist es möglich, ein Routing-Protokoll für die Verbindungen zu den verschiedenen Routern zu aktivieren und auf den übrigen 98 Cisco Spokes weiterhin ODR auszuführen.
Abbildung 6: ODR mit mehreren Anbietern 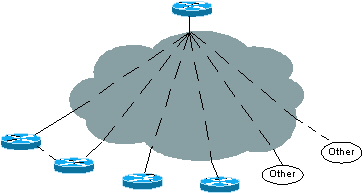
Der mit den 98 Cisco Routern verbundene Hub-Router erhält Subnetz-Updates über ODR und Routing-Protokoll-Updates von den beiden anderen Routern. Die Verbindungen zwischen den verschiedenen Routern müssen sich in separaten Point-to-Point- oder Point-to-Multipoint-Subnetzen befinden.
Probleme mit zukünftigem Wachstum
Wenn ein Unternehmen ODR auf 100 Spokes betreibt, möchte es seine Topologie möglicherweise von einem Hub-and-Spoke-Netzwerk aus ändern. Sie könnten sich beispielsweise für ein Upgrade eines Spokes auf eine größere Plattform entscheiden, wodurch dieser ein Hub für 20 weitere neue Spokes wurde.
Abbildung 7: Zukünftiges Wachstum 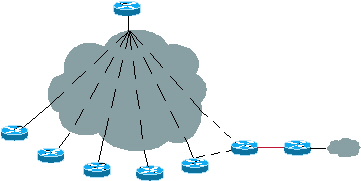
Es ist möglich, ein Routing-Protokoll auf dem neuen Hub auszuführen und das ODR-Design unverändert beizubehalten. Wenn der neue Hub 20 oder mehr neue Spokes unterstützt, kann ODR auf dem neuen Hub ausgeführt werden. Der neue Hub kann über ODR Informationen zu diesen neuen Spoke-Subnetzen erhalten und diese Informationen über ein anderes Routing-Protokoll an den ursprünglichen Hub weitergeben.
Diese Situation ist ähnlich, wenn ODR mit zwei Hubs beginnt. Der Aufwand für das Ändern von Protokollen entfällt. Im Prinzip kann ODR so lange ausgeführt werden, wie der Router ein Stub ist.
Leistung
Mehrere Einstellungen können für eine schnellere Konvergenz und eine bessere Leistung bei der Ausführung von ODR angepasst werden.
Timer-Anpassung für schnellere Konvergenz
In einer großen ODR-Umgebung sollten die ODR-Timer für eine schnellere Konvergenz angepasst und die Timer für das CDP-Update vom Hub zum Spoke erhöht werden, um die CPU-Leistung des Hubs zu minimieren.
Hub-Router
Der CDP-Aktualisierungs-Timer sollte standardmäßig auf 60 Sekunden festgelegt werden, um die Datenmenge vom Hub zu den Stationen zu reduzieren. Die Haltezeit sollte auf den Maximalwert (255 Sekunden) erhöht werden. Da der Hub-Router zu viele CDP-Adjacency-Tabellen verwalten muss und falls einige Nachbarn ausfallen, sollten Sie die CDP-Einträge nicht für 255 Sekunden aus dem Speicher löschen (die maximal zulässige Haltezeit). Diese Konfiguration bietet dem Hub-Router Flexibilität, da bei einem erneuten Eintreffen des Nachbarn innerhalb von vier Minuten die CDP-Adjacency nicht neu erstellt werden muss. Der alte Tabelleneintrag kann verwendet und der Holddown-Timer aktualisiert werden.
Das nachfolgende Beispiel zeigt eine IP-Konfigurationsvorlage für einen zentralen Router:
cdp holdtime 255
router odr
timers basic 8 24 0 1 /* odr timer's are update, invalid, hold down, flush
router eigrp 1
network 10.0.0.0
redistribute odr
default-metric 1 1 1 1 1
Es gibt drei permanente virtuelle Schaltungen (PVCs) von jedem Remote-Standort (Lager, Region und Lager). Zwei der PVCs sind auf zwei separate zentrale Router verteilt. Die dritte PVC wird an einen PayPoint-Router gesendet. Für Datenverkehr, der für das PayPoint-Netzwerk bestimmt ist, muss die PVC zur PayPoint-Route verwendet werden. Die beiden anderen PVCs dienen als primäre und Backup-Funktion für den gesamten anderen Datenverkehr. Basierend auf diesen Anforderungen ist die Konfigurationsvorlage unten für jeden Remote-Router zu entnehmen.
Es ist sehr wichtig, die ODR-Timer wie ungültig, holddown und Flush anzupassen, um eine schnellere Konvergenz zu erreichen. Auch wenn CDP nach der Konfiguration der Router-ID kein IP-Präfix sendet, sollte der ODR-Aktualisierungs-Timer mit dem benachbarten CDP-Aktualisierungs-Timer übereinstimmen, da der Konvergenzzeitgeber nur bei einem Aktualisierungs-Timer festgelegt werden kann. Dieser Timer unterscheidet sich vom CDP-Timer und kann nur für eine schnellere Konvergenz verwendet werden.
Spoke-Router
Da die Spokes ODR-Updates in CDP-Paketen senden, sollte der Timer für CDP-Updates für eine schnellere Konvergenz sehr klein gehalten werden. In einer echten Spoke-Umgebung gibt es keine Beschränkung für Ausfallzeiten für den CDP-Nachbarn, da nur wenige Einträge für das Spoke in der CDP-Tabelle gespeichert sind. Die maximale Holddown-Zeit von 255 Sekunden wird empfohlen, sodass bei einem Ausfall des Hub-PVC innerhalb von vier Minuten keine neue CDP-Adjacency erforderlich ist, da der alte Tabelleneintrag verwendet werden kann.
Das nachfolgende Beispiel zeigt eine IP-Konfigurationsvorlage für einen Remote-Standort:
cdp timer 8
cdp holdtime 255
interface serial 0
encapsulation frame-relay
cdp enable
interface serial 0.1 point /* Primary PVC */
ip address 10.x.x.x 255.255.255.0
frame-relay interface-dlci XX
interface serial 0.2 point /* Secondary PVC */
ip address 10.y.y.y 255.255.255.0
frame-relay interface-dlci XX
interface bri 0
interface BRI0
description Backup ISDN for frame-relay
ip address 10.c.d.e 255.255.255.0
encapsulation PPP
dialer idle-timeout 240
dialer wait-for-carrier-time 60
dialer map IP 10.x.x.x name ROUTER2 broadcast xxxxxxxxx
ppp authentication chap
dialer-group 1
isdn spid1 xxxxxxx
isdn spid2 xxxxxxx
access-list 101 permit ip 0.0.0.0 255.255.255.255 0.0.0.0 255.255.255.255
dialer-list 1 LIST 101
/* following are the static routes that need to be configured on the remote routers
ip route 0.0.0.0 0.0.0.0 10.x.x.x
ip route 0.0.0.0 0.0.0.0 10.y.y.y
ip route 0.0.0.0 0.0.0.0 bri 0 100
ip classless
Die statischen Standardrouten sind bei Verwendung von IOS 12.0.5T oder höher nicht erforderlich, da der Hub-Router die Standardroute automatisch an alle Stationen sendet.
Filtern und Zusammenfassen von ODR-Routen
ODR-Routen können gefiltert werden, bevor sie in den Kern gelangen. Verwenden Sie den Befehl distribute-list in. Alle verbundenen Subnetze der Stationen sollten zusammengefasst werden, wenn sie in den Kern gelangen. Wenn keine Zusammenfassung möglich ist, können unnötige Routen am Hub-Router gefiltert werden. In mehreren Hub-Netzwerken können die Stationen die verbundene Schnittstelle ankündigen, die der Link zu einem anderen Hub ist.
In dieser Situation muss der Befehl distribute-list angewendet werden, damit der Hub diese Routen nicht in die Routing-Tabelle überträgt. Wenn ODR an den Hub weitergeleitet wird, werden diese Informationen nicht in den Core übertragen.
Telco-Timer-Anpassung
Es ist wichtig, den Telco-Timer anzupassen, um die Konvergenzzeit für die Stationen zu erhöhen. Wenn das PVC von der Hub-Seite ausfällt, sollten die Speichen es schnell erkennen können, um zum zweiten Hub zu wechseln.
CPU-Leistung
Der ODR-Prozess beansprucht nicht viel CPU-Auslastung. ODR wurde für ca. 1.000 Nachbarn getestet, wobei die CPU-Auslastung drei bis vier Prozent betrug. Die aggressive Timer-Einstellung des ODR am Hub trägt zu einer schnelleren Konvergenz bei. Wenn die Standardeinstellungen verwendet werden, bleibt die CPU-Auslastung bei 0 bis 1 %.
Selbst bei aggressiven ODR- und CDP-Timern zeigt die folgende Ausgabe, dass die CPU-Auslastung nicht hoch war. Dieser Test wurde mit einem 150-MHz-Prozessor auf einem Cisco 7206 durchgeführt.
Hub# show proc cpu
CPU utilization for five seconds: 4%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11588036 15783316 734 0.73% 1.74% 1.95% 0 CDP Protocol
.
.
48 3864 5736 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 3%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11588484 15783850 734 2.21% 1.83% 1.96% 0 CDP Protocol
.
.
48 3864 5736 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 2%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11588676 15784090 734 1.31% 1.79% 1.95% 0 CDP Protocol
.
.
48 3864 5736 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 1%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11588824 15784283 734 0.65% 1.76% 1.94% 0 CDP Protocol
.
.
48 3864 5737 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 3%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11589004 15784473 734 1.96% 1.85% 1.95% 0 CDP Protocol
.
.
48 3864 5737 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 3%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11589188 15784661 734 1.63% 1.83% 1.94% 0 CDP Protocol
.
.
48 3864 5737 673 0.00% 0.00% 0.00% 0 ODR Router
Verbesserungen
Die ODR-Version vor Cisco IOS 12.0.5T hatte einige Einschränkungen. Nachfolgend finden Sie eine Liste der Verbesserungen in Cisco IOS 12.0.5T und höher:
-
Vor CSCdy48736 werden sekundäre Subnetze in einem CDP-Update als /32 angekündigt. Dies ist in 12.2.13T und höher behoben.
-
CDP-Hubs propagieren jetzt Standardrouten an die Stationen, sodass in den Stationen keine statischen Standardrouten mehr hinzugefügt werden müssen. Die Konvergenzzeit nimmt erheblich zu. Wenn der nächste Hop ausfällt, erkennt der Spoke ihn schnell per ODR und konvergiert ihn. Diese Funktion wurde in 12.0.5T durch den Bug CSCdk91586 hinzugefügt.
-
Wenn die Verbindung zwischen Hub und Spoke IP-unnummeriert ist, wird die vom Hub gesendete Standardroute möglicherweise nicht in den Stationen angezeigt. Dieser Fehler CSCdx66917 wurde in IOS 12.2.14, 12.2.14T und höher behoben.
-
Um die ODR-Entfernung auf den Stationen zu erhöhen/zu verringern, sodass sie einen Hub dem anderen vorziehen können, wurde ein Vorschlag gemacht, der über CSCdr35460 nachverfolgt wird. Der Code wurde bereits getestet und wird demnächst für Kunden verfügbar sein.
 Feedback
Feedback