Erläuterung der Fehler bei der zyklischen Redundanzprüfung auf Nexus Switches
Download-Optionen
-
ePub (647.4 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
Dieses Dokument beschreibt CRC-Fehler (Cyclic Redundancy Check), die an den Schnittstellenzählern beobachtet wurden, sowie die Statistiken der Cisco Nexus Switches.
Voraussetzungen
Anforderungen
Cisco empfiehlt, sich mit den Grundlagen von Ethernet-Switching und der Cisco NX-OS-CLI (Command Line Interface) vertraut zu machen. Weitere Informationen finden Sie in einem der folgenden Dokumente:
- Cisco Nexus 9000 NX-OS - Grundlagen der Konfiguration, Version 10.2(x)
- Cisco Nexus Serie 9000 - NX-OS - Grundlagen der Konfiguration, Version 9.3(x)
- Cisco Nexus Serie 9000 - NX-OS - Grundlagen der Konfiguration, Version 9.2(x)
- Cisco Nexus Serie 9000: NX-OS - Grundlagen der Konfiguration, Version 7.x
Verwendete Komponenten
Die Informationen in diesem Dokument basierend auf folgenden Software- und Hardware-Versionen:
- Switches der Serie Nexus 9000 ab NX-OS Softwareversion 9.3(8)
- Nexus Switches der Serie 3000 ab NX-OS Softwareversion 9.3(8)
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle kennen.
Hintergrundinformationen
In diesem Dokument werden Details zu CRC-Fehlern (Cyclic Redundancy Check) beschrieben, die an den Schnittstellenzählern von Cisco Switches der Nexus-Serie festgestellt wurden. In diesem Dokument wird beschrieben, was ein CRC ist, wie er im FCS-Feld (Frame Check Sequence) von Ethernet-Frames verwendet wird, wie sich CRC-Fehler auf Nexus-Switches manifestieren und wie CRC-Fehler beim Store-and-Forward-Switching interagieren. In diesem Artikel werden außerdem Szenarien für das Cut-Through-Switching, die wahrscheinlichsten Ursachen für CRC-Fehler und die Fehlerbehebung und Behebung von CRC-Fehlern beschrieben.
Relevante Hardware
Die Informationen in diesem Dokument gelten für alle Switches der Cisco Nexus-Serie. Einige der Informationen in diesem Dokument können auch auf andere Cisco Routing- und Switching-Plattformen wie Cisco Catalyst Router und Switches angewendet werden.
CRC-Definition
Ein CRC ist ein Fehlererkennungsmechanismus, der häufig in Computer- und Speichernetzwerken verwendet wird, um während der Übertragung geänderte oder beschädigte Daten zu identifizieren. Wenn ein mit dem Netzwerk verbundenes Gerät Daten übertragen muss, führt das Gerät einen Berechnungsalgorithmus aus, der auf zyklischen Codes basiert und die Daten mit einer Nummer fester Länge vergleicht. Diese Nummer mit fester Länge wird als CRC-Wert bezeichnet, umgangssprachlich wird sie jedoch oft kurz CRC genannt. Dieser CRC-Wert wird an die Daten angehängt und über das Netzwerk an ein anderes Gerät übertragen. Dieses Remote-Gerät führt den gleichen zyklischen Codealgorithmus für die Daten aus und vergleicht den resultierenden Wert mit dem an die Daten angehängten CRC. Wenn beide Werte übereinstimmen, geht das Remote-Gerät davon aus, dass die Daten ohne Beschädigung über das Netzwerk übertragen wurden. Stimmen die Werte nicht überein, geht das Remote-Gerät davon aus, dass die Daten bei der Übertragung über das Netzwerk beschädigt wurden. Diese beschädigten Daten können nicht vertrauenswürdig sein und werden verworfen.
CRCs werden für die Fehlererkennung in mehreren Netzwerk-Computertechnologien verwendet, z. B. Ethernet (sowohl kabelgebundene als auch drahtlose Varianten), Token Ring, Asynchronous Transfer Mode (ATM) und Frame Relay. Ethernet-Frames haben ein 32-Bit-FCS-Feld (Frame Check Sequence) am Ende des Frames (unmittelbar nach der Nutzlast des Frames), in das ein 32-Bit-CRC-Wert eingefügt wird.
Nehmen wir als Beispiel ein Szenario, bei dem zwei Hosts mit der Bezeichnung Host-A und Host-B direkt über ihre Netzwerkschnittstellenkarten (NICs) miteinander verbunden sind. Host-A muss den Satz "Dies ist ein Beispiel" über das Netzwerk an Host-B senden. Host-A erstellt einen Ethernet-Frame, der an Host-B gerichtet ist, mit der Nutzlast "Dies ist ein Beispiel" und berechnet, dass der CRC-Wert des Frames ein Hexadezimalwert von 0xABCD ist. Host-A fügt den CRC-Wert 0xABCD in das FCS-Feld des Ethernet-Frames ein und überträgt dann den Ethernet-Frame von der Host-A-NIC an Host-B.
Wenn Host-B diesen Frame empfängt, kann er den CRC-Wert des Frames mit dem exakt gleichen Algorithmus wie Host-A berechnen. Host-B berechnet, dass der CRC-Wert des Frames ein Hexadezimalwert von 0xABCD ist, was Host-B anzeigt, dass der Ethernet-Frame nicht beschädigt war, während der Frame an Host-B übertragen wurde.
CRC-Fehlerdefinition
Ein CRC-Fehler tritt auf, wenn ein Gerät (entweder ein Netzwerkgerät oder ein mit dem Netzwerk verbundener Host) einen Ethernet-Frame mit einem CRC-Wert im FCS-Feld des Frames empfängt, der nicht mit dem vom Gerät für den Frame berechneten CRC-Wert übereinstimmt.
Dieses Konzept lässt sich am besten anhand eines Beispiels veranschaulichen. Nehmen wir ein Szenario, in dem zwei Hosts mit den Namen Host-A und Host-B direkt über ihre Netzwerkschnittstellenkarten (NICs) miteinander verbunden sind. Host-A muss den Satz "Dies ist ein Beispiel" über das Netzwerk an Host-B senden. Host-A erstellt einen Ethernet-Frame, der an Host-B gerichtet ist, mit der Nutzlast "Dies ist ein Beispiel" und berechnet, dass der CRC-Wert des Frames der Hexadezimalwert 0xABCD ist. Host-A fügt den CRC-Wert 0xABCD in das FCS-Feld des Ethernet-Frames ein und überträgt dann den Ethernet-Frame von der Host-A-NIC an Host-B.
Durch eine Beschädigung der physischen Medien, die Host-A mit Host-B verbinden, wird jedoch der Frame-Inhalt beschädigt, sodass der Satz im Frame in "This was an example" (Dies war ein Beispiel) und nicht in die gewünschte Nutzlast "This is an example" (Dies ist ein Beispiel) geändert wird.
Wenn Host-B diesen Frame empfängt, kann er den CRC-Wert des Frames berechnen und die beschädigte Nutzlast in die Berechnung einbeziehen. Host-B berechnet, dass der CRC-Wert des Frames ein Hexadezimalwert von 0xDEAD ist, der sich vom 0xABCD-CRC-Wert im FCS-Feld des Ethernet-Frames unterscheidet. Dieser Unterschied in den CRC-Werten weist Host-B darauf hin, dass der Ethernet-Frame beschädigt war, während der Frame an Host-B übertragen wurde. Daher kann Host-B dem Inhalt dieses Ethernet-Frames nicht vertrauen und ihn daher verwerfen. Host-B kann in der Regel auch eine Art Fehlerzähler auf seiner Netzwerkkarte (NIC) erhöhen, z. B. die Zähler für "Eingabefehler", "CRC-Fehler" oder "RX-Fehler".
Häufige Symptome von CRC-Fehlern
CRC-Fehler zeigen sich in der Regel auf zwei Arten:
- Zähler für inkrementelle oder von Null verschiedene Fehler an Schnittstellen von mit dem Netzwerk verbundenen Geräten.
- Paket-/Frame-Verlust für Datenverkehr, der das Netzwerk durchquert, da Geräte mit dem Netzwerk verbunden sind, die beschädigte Frames verwerfen.
Diese Fehler zeigen sich auf leicht unterschiedliche Weise, je nachdem, mit welchem Gerät Sie gerade arbeiten. Diese Unterabschnitte werden für jeden Gerätetyp ausführlich beschrieben.
Fehler auf Windows-Hosts empfangen
CRC-Fehler auf Windows-Hosts werden in der Regel als Zähler für empfangene Fehler ungleich null angezeigt, der in der Ausgabe des Befehls netstat -e von der Eingabeaufforderung aus angezeigt wird. Ein Beispiel für einen Leistungsindikator "Empfangene Fehler", der ungleich null ist, von der Eingabeaufforderung eines Windows-Hosts ist:
>netstat -e
Interface Statistics
Received Sent
Bytes 1116139893 3374201234
Unicast packets 101276400 49751195
Non-unicast packets 0 0
Discards 0 0
Errors 47294 0
Unknown protocols 0
Die Netzwerkkarte und ihr jeweiliger Treiber müssen die Erfassung von CRC-Fehlern unterstützen, die von der Netzwerkkarte empfangen wurden, damit die Anzahl der empfangenen Fehler, die vom Befehl netstat -e gemeldet wurden, korrekt ist. Die meisten modernen NICs und ihre jeweiligen Treiber unterstützen eine genaue Erfassung der CRC-Fehler, die von der NIC empfangen werden.
RX-Fehler auf Linux-Hosts
CRC-Fehler auf Linux-Hosts werden in der Regel als Zähler für "RX-Fehler" ungleich null angezeigt, der in der Ausgabe des Befehls ifconfig angezeigt wird. Ein Beispiel für einen RX-Fehlerzähler ungleich null von einem Linux-Host ist hier:
$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.0.2.10 netmask 255.255.255.128 broadcast 192.0.2.255
inet6 fe80::10 prefixlen 64 scopeid 0x20<link>
ether 08:62:66:be:48:9b txqueuelen 1000 (Ethernet)
RX packets 591511682 bytes 214790684016 (200.0 GiB)
RX errors 478920 dropped 0 overruns 0 frame 0
TX packets 85495109 bytes 288004112030 (268.2 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
CRC-Fehler auf Linux-Hosts können sich auch als Zähler für "RX-Fehler" ungleich null manifestieren, der in der Ausgabe des Befehls ip -s link show angezeigt wird. Ein Beispiel für einen RX-Fehlerzähler ungleich null von einem Linux-Host ist hier:
$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 08:62:66:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
32246366102 444908978 478920 647 0 419445867
TX: bytes packets errors dropped carrier collsns
3352693923 30185715 0 0 0 0
altname enp11s0
Die Netzwerkkarte und ihr jeweiliger Treiber müssen die Erfassung von CRC-Fehlern unterstützen, die von der Netzwerkkarte empfangen wurden, damit die Anzahl der RX-Fehler, die von den Befehlen ifconfig oder ip -s link show gemeldet werden, korrekt ist. Die meisten modernen NICs und ihre jeweiligen Treiber unterstützen eine genaue Erfassung der CRC-Fehler, die von der NIC empfangen werden.
CRC-Fehler auf Netzwerkgeräten
Netzwerkgeräte können in einem von zwei Weiterleitungsmodi betrieben werden:
- Store-and-Forward-Weiterleitungsmodus
- Cut-Through-Weiterleitungsmodus
Die Art und Weise, wie ein Netzwerkgerät einen empfangenen CRC-Fehler behandelt, unterscheidet sich je nach seinen Weiterleitungsmodi. In den Unterabschnitten wird das spezifische Verhalten für jeden Weiterleitungsmodus beschrieben.
Eingabefehler auf Store-and-Forward-Netzwerkgeräten
Wenn ein Netzwerkgerät, das in einem Store-and-Forward-Weiterleitungsmodus arbeitet, einen Frame empfängt, kann das Netzwerkgerät den gesamten Frame ("Store") puffern, bevor Sie den CRC-Wert des Frames validieren, eine Weiterleitungsentscheidung für den Frame treffen und den Frame über eine Schnittstelle ("Forward") übertragen. Wenn ein Netzwerkgerät, das in einem Store-and-Forward-Weiterleitungsmodus arbeitet, einen beschädigten Frame mit einem falschen CRC-Wert an einer bestimmten Schnittstelle empfängt, kann es den Frame verwerfen und den Zähler "Eingabefehler" an der Schnittstelle inkrementieren.
Mit anderen Worten: Beschädigte Ethernet-Frames werden nicht von Netzwerkgeräten weitergeleitet, die im Store-and-Forward-Weiterleitungsmodus betrieben werden. Sie werden beim Eintritt verworfen.
Die Cisco Nexus Switches der Serien 7000 und 7700 werden im Store-and-Forward-Weiterleitungsmodus betrieben. Ein Beispiel für einen Zähler für Eingabefehler ungleich null und einen Zähler für CRC/FCS ungleich null von einem Switch der Serie Nexus 7000 oder 7700 finden Sie hier:
switch# show interface
<snip>
Ethernet1/1 is up
RX
241052345 unicast packets 5236252 multicast packets 5 broadcast packets
245794858 input packets 17901276787 bytes
0 jumbo packets 0 storm suppression packets
0 runts 0 giants 579204 CRC/FCS 0 no buffer
579204 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
CRC-Fehler können sich auch in der Ausgabe von show interface counters errors als ein von Null verschiedener "FCS-Err"-Zähler manifestieren. Der Zähler "Rcv-Err" in der Ausgabe dieses Befehls kann auch einen Wert ungleich null haben, der die Summe aller von der Schnittstelle empfangenen Eingabefehler (CRC oder anders) ist. Ein Beispiel dafür ist hier zu sehen:
switch# show interface counters errors
<snip>
--------------------------------------------------------------------------------
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards
--------------------------------------------------------------------------------
Eth1/1 0 579204 0 579204 0 0
Eingabe- und Ausgabefehler bei Cut-Through-Netzwerkgeräten
Wenn ein Netzwerkgerät, das in einem Cut-Through-Weiterleitungsmodus arbeitet, beginnt, einen Frame zu empfangen, kann das Netzwerkgerät eine Weiterleitungsentscheidung über den Frame-Header treffen und damit beginnen, den Frame aus einer Schnittstelle zu übertragen, sobald es genug vom Frame empfängt, um eine gültige Weiterleitungsentscheidung zu treffen. Da Frame- und Paket-Header am Anfang des Frames stehen, wird diese Weiterleitungsentscheidung in der Regel getroffen, bevor die Nutzlast des Frames empfangen wird.
Das FCS-Feld eines Ethernet-Frames befindet sich am Ende des Frames, unmittelbar nach dessen Nutzlast. Daher kann ein in einem Cut-Through-Weiterleitungsmodus arbeitendes Netzwerkgerät bereits begonnen haben, den Frame aus einer anderen Schnittstelle zu übertragen, bis es die CRC des Frames berechnen kann. Wenn die vom Netzwerkgerät für den Frame berechnete CRC nicht mit dem im FCS-Feld vorhandenen CRC-Wert übereinstimmt, bedeutet dies, dass das Netzwerkgerät einen beschädigten Frame in das Netzwerk weitergeleitet hat. In diesem Fall kann das Netzwerkgerät zwei Zähler inkrementieren:
- Der Zähler "Input Errors" (Eingabefehler) auf der Schnittstelle, auf der der beschädigte Frame ursprünglich empfangen wurde.
- Der Zähler "Output Errors" (Ausgabefehler) auf allen Schnittstellen, auf denen der beschädigte Frame übertragen wurde. Bei Unicast-Datenverkehr kann dies in der Regel eine einzelne Schnittstelle sein. Bei Broadcast-, Multicast- oder unbekanntem Unicast-Datenverkehr kann es sich jedoch um eine oder mehrere Schnittstellen handeln.
Ein Beispiel hierfür ist hier dargestellt, wobei die Ausgabe des Befehls show interface anzeigt, dass mehrere beschädigte Frames auf Ethernet1/1 des Netzwerkgeräts empfangen und aufgrund des Cut-Through-Weiterleitungsmodus des Netzwerkgeräts aus Ethernet1/2 übertragen wurden:
switch# show interface
<snip>
Ethernet1/1 is up
RX
46739903 unicast packets 29596632 multicast packets 0 broadcast packets
76336535 input packets 6743810714 bytes
15 jumbo packets 0 storm suppression bytes
0 runts 0 giants 47294 CRC 0 no buffer
47294 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
Ethernet1/2 is up
TX
46091721 unicast packets 2852390 multicast packets 102619 broadcast packets
49046730 output packets 3859955290 bytes
50230 jumbo packets
47294 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
CRC-Fehler können sich auch als ein von Null verschiedener "FCS-Err"-Zähler an der Eingangsschnittstelle und von Null verschiedener "Xmit-Err"-Zähler an Ausgangsschnittstellen in der Ausgabe von "show interface counters errors" äußern. Der Zähler "Rcv-Err" an der Eingangsschnittstelle in der Ausgabe dieses Befehls kann auch einen Wert ungleich null haben, der die Summe aller von der Schnittstelle empfangenen Eingabefehler (CRC oder anders) ist. Ein Beispiel dafür ist hier zu sehen:
switch# show interface counters errors
<snip>
--------------------------------------------------------------------------------
Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards
--------------------------------------------------------------------------------
Eth1/1 0 47294 0 47294 0 0
Eth1/2 0 0 47294 0 0 0
Das Netzwerkgerät kann den CRC-Wert im FCS-Feld des Frames auch auf eine bestimmte Weise ändern, die den Upstream-Netzwerkgeräten signalisiert, dass dieser Frame beschädigt ist. Dieses Verhalten wird als "Stomping" des CRC bezeichnet. Die genaue Art und Weise, wie der CRC geändert wird, variiert von Plattform zu Plattform, berechnet jedoch im Allgemeinen den CRC-Wert des beschädigten Frames, invertiert diesen Wert und fügt ihn in das FCS-Feld des Frames ein. Hier ein Beispiel:
Original Frame's CRC: 0xABCD (1010101111001101)
Corrupted Frame's CRC: 0xDEAD (1101111010101101)
Corrupted Frame's Stomped CRC: 0x2152 (0010000101010010)
Als Folge dieses Verhaltens können Netzwerkgeräte, die im Cut-Through-Weiterleitungsmodus arbeiten, einen beschädigten Frame in einem Netzwerk propagieren. Wenn ein Netzwerk aus mehreren Netzwerkgeräten besteht, die im Cut-Through-Weiterleitungsmodus betrieben werden, kann ein einzelner beschädigter Frame dazu führen, dass die Zähler für Eingabefehler und Ausgabefehler auf mehreren Netzwerkgeräten im Netzwerk inkrementiert werden.
Nachverfolgen und Isolieren von CRC-Fehlern
Der erste Schritt zum Identifizieren und Beheben der Ursache von CRC-Fehlern besteht darin, die Quelle der CRC-Fehler auf eine bestimmte Verbindung zwischen zwei Geräten in Ihrem Netzwerk zu isolieren. Eine mit dieser Verbindung verbundene Einrichtung kann einen Schnittstellenausgangsfehlerzähler mit einem Wert von Null oder nicht inkrementierend aufweisen, während die andere mit dieser Verbindung verbundene Einrichtung einen nicht-Null- oder inkrementierenden Schnittstelleneingangsfehlerzähler aufweisen kann. Dies deutet darauf hin, dass Datenverkehr die Schnittstelle eines Geräts intakt verlässt, zum Zeitpunkt der Übertragung an das entfernte Gerät beschädigt ist und von der Eingangsschnittstelle des anderen Geräts auf der Verbindung als Eingabefehler gezählt wird.
Diese Verbindung in einem Netzwerk zu identifizieren, das aus Netzwerkgeräten besteht, die im Store-and-Forward-Weiterleitungsmodus arbeiten, ist eine einfache Aufgabe. Wenn Sie diesen Link jedoch in einem Netzwerk identifizieren, das aus Netzwerkgeräten besteht, die im Cut-Through-Weiterleitungsmodus betrieben werden, ist dies schwieriger, da viele Netzwerkgeräte über Eingabe- und Ausgabefehlerzähler verfügen können, die ungleich null sind. Ein Beispiel für dieses Phänomen ist in der Topologie zu sehen, in der die rot markierte Verbindung beschädigt wird, sodass der Datenverkehr über die Verbindung beschädigt wird. Mit einem roten "I" gekennzeichnete Schnittstellen weisen auf Schnittstellen hin, die Eingabefehler ungleich null aufweisen können, während mit einem blauen "O" gekennzeichnete Schnittstellen auf Schnittstellen hinweisen, die Ausgabefehler ungleich null aufweisen können.
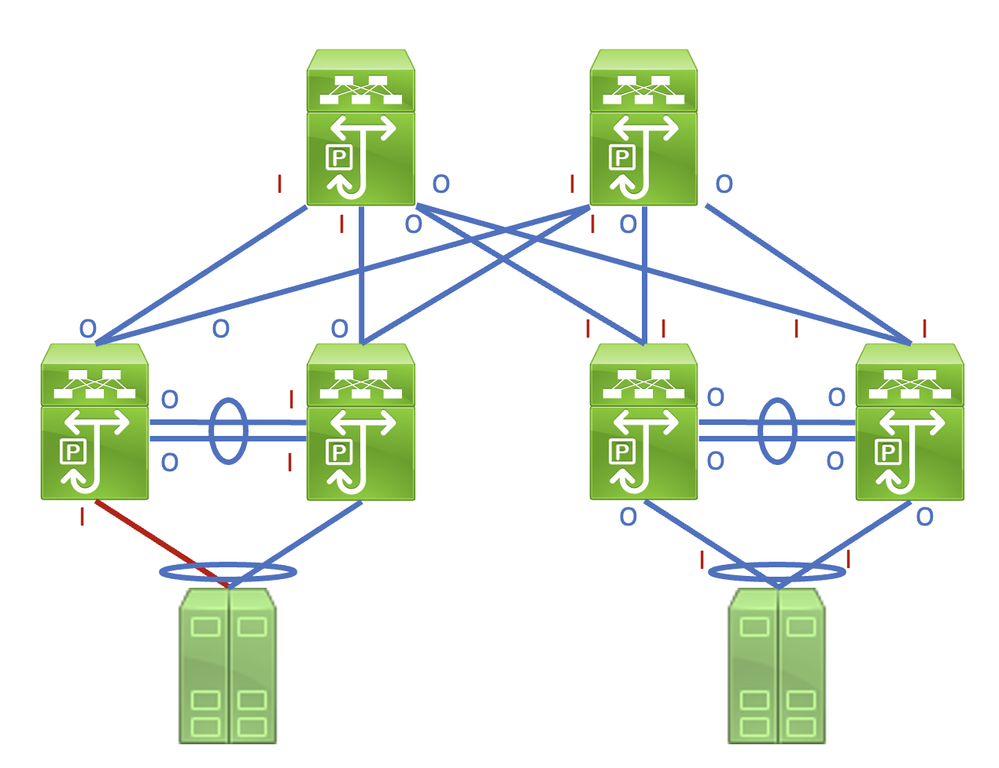
Dieses Dokument beschreibt CRC-Fehler (Cyclic Redundancy Check), die an den Schnittstellenzählern beobachtet wurden, sowie die Statistiken der Cisco Nexus Switches.
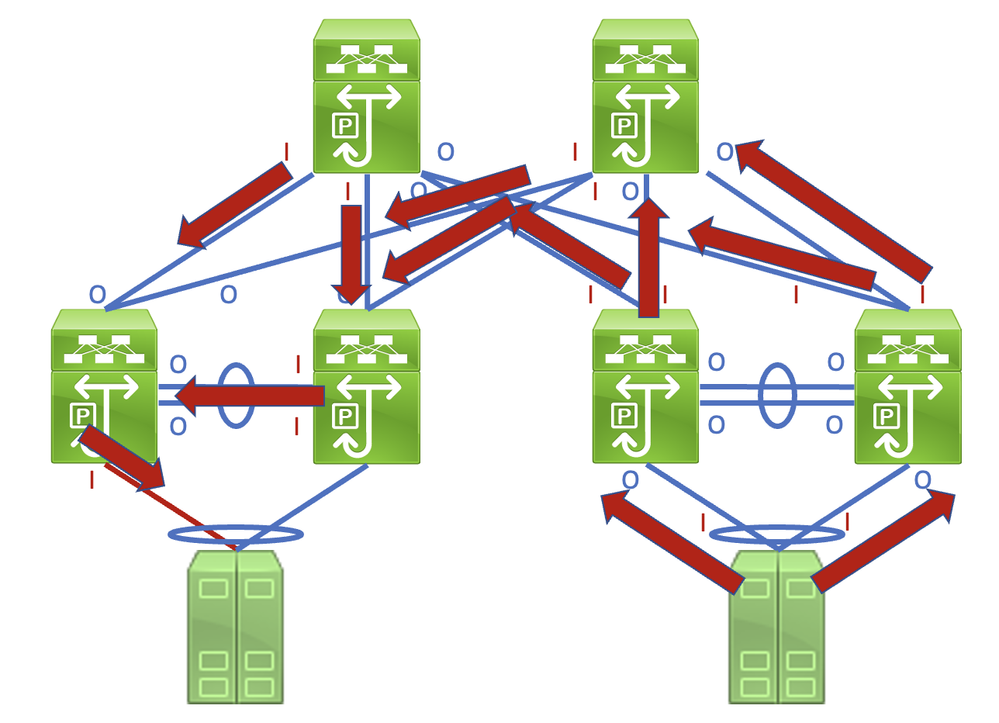
Ein detaillierter Prozess zum Aufspüren und Identifizieren einer beschädigten Verbindung wird am besten anhand eines Beispiels veranschaulicht. Beachten Sie die folgende Topologie:
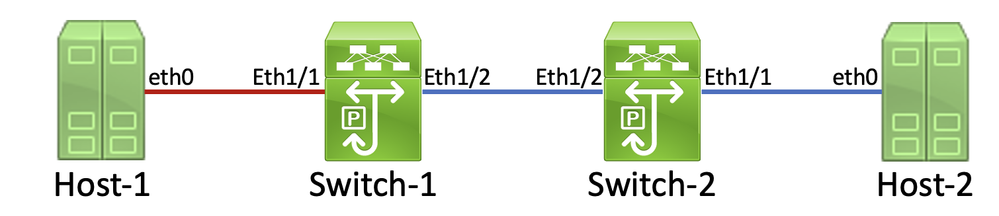
In dieser Topologie ist die Schnittstelle Ethernet1/1 eines Nexus-Switches mit dem Namen Switch-1 über die Netzwerkkarte eth0 von Host-1 mit einem Host mit dem Namen Host-1 verbunden. Die Schnittstelle Ethernet1/2 von Switch-1 ist über die Schnittstelle Ethernet1/2 von Switch-2 mit einem zweiten Nexus-Switch namens Switch-2 verbunden. Die Schnittstelle Ethernet1/1 von Switch-2 ist über die Host-2-NIC eth0 mit einem Host mit dem Namen Host-2 verbunden.
Die Verbindung zwischen Host-1 und Switch-1 über die Ethernet1/1-Schnittstelle von Switch-1 ist beschädigt und verursacht eine zeitweilige Beschädigung des Datenverkehrs, der die Verbindung durchquert. Ob die Verbindung jedoch beschädigt ist, ist an dieser Stelle nicht bekannt. Sie müssen den Pfad verfolgen, den die beschädigten Frames im Netzwerk hinterlassen, durch Eingabe- und Ausgabefehlerzähler, die ungleich null sind oder inkrementiert sind, um die beschädigte Verbindung in diesem Netzwerk zu ermitteln.
In diesem Beispiel meldet Host-2 NIC, dass er CRC-Fehler empfängt.
Host-2$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:50:56:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
32246366102 444908978 478920 647 0 419445867
TX: bytes packets errors dropped carrier collsns
3352693923 30185715 0 0 0 0
altname enp11s0
Sie wissen, dass eine Host-2-Netzwerkkarte über die Schnittstelle Ethernet1/1 mit Switch-2 verbunden ist. Mit dem Befehl show interface können Sie überprüfen, ob für die Schnittstelle Ethernet1/1 ein Zähler für Ausgabefehler ungleich 0 (null) angegeben ist.
Switch-2# show interface
<snip>
Ethernet1/1 is up
admin state is up, Dedicated Interface
RX
30184570 unicast packets 872 multicast packets 273 broadcast packets
30185715 input packets 3352693923 bytes
0 jumbo packets 0 storm suppression bytes
0 runts 0 giants 0 CRC 0 no buffer
0 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
TX
444907944 unicast packets 932 multicast packets 102 broadcast packets
444908978 output packets 32246366102 bytes
0 jumbo packets
478920 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
Da der Zähler für Ausgabefehler der Schnittstelle Ethernet1/1 nicht Null ist, gibt es höchstwahrscheinlich eine andere Schnittstelle von Switch-2, die einen Zähler für Eingabefehler ungleich null hat. Mit dem Befehl show interface counters errors non-zero (Schnittstellenzähler anzeigen, ungleich null) können Sie ermitteln, ob Schnittstellen von Switch-2 über einen Eingabefehlerzähler ungleich null verfügen.
Switch-2# show interface counters errors non-zero <snip> -------------------------------------------------------------------------------- Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards -------------------------------------------------------------------------------- Eth1/1 0 0 478920 0 0 0 Eth1/2 0 478920 0 478920 0 0 -------------------------------------------------------------------------------- Port Single-Col Multi-Col Late-Col Exces-Col Carri-Sen Runts -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port Giants SQETest-Err Deferred-Tx IntMacTx-Er IntMacRx-Er Symbol-Err -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port InDiscards --------------------------------------------------------------------------------
Wie Sie sehen, hat Ethernet1/2 von Switch-2 einen Eingabefehlerzähler ungleich null. Dies deutet darauf hin, dass Switch-2 beschädigten Datenverkehr über diese Schnittstelle empfängt. Sie können überprüfen, welches Gerät über das Cisco Discovery Protocol (CDP) oder Link Local Discovery Protocol (LLDP) mit Ethernet1/2 von Switch-2 verbunden ist. Ein Beispiel hierfür ist der Befehl show cdp neighbors.
Switch-2# show cdp neighbors
<snip>
Capability Codes: R - Router, T - Trans-Bridge, B - Source-Route-Bridge
S - Switch, H - Host, I - IGMP, r - Repeater,
V - VoIP-Phone, D - Remotely-Managed-Device,
s - Supports-STP-Dispute
Device-ID Local Intrfce Hldtme Capability Platform Port ID
Switch-1(FDO12345678)
Eth1/2 125 R S I s N9K-C93180YC- Eth1/2
Sie wissen jetzt, dass Switch-2 beschädigten Datenverkehr über seine Ethernet1/2-Schnittstelle von der Ethernet1/2-Schnittstelle von Switch-1 empfängt, aber Sie wissen noch nicht, ob die Verbindung zwischen Ethernet1/2 von Switch-1 und Ethernet1/2 von Switch-2 beschädigt ist und die Beschädigung verursacht, oder ob Switch-1 ein Cut-Through-Switch ist, der beschädigten Datenverkehr weiterleitet und empfängt. Sie müssen sich bei Switch-1 anmelden, um dies zu überprüfen.
Mit dem Befehl show interfaces können Sie überprüfen, ob die Ethernet1/2-Schnittstelle von Switch-1 einen Zähler für Ausgabefehler aufweist, der ungleich null ist.
Switch-1# show interface
<snip>
Ethernet1/2 is up
admin state is up, Dedicated Interface
RX
30581666 unicast packets 178 multicast packets 931 broadcast packets
30582775 input packets 3352693923 bytes
0 jumbo packets 0 storm suppression bytes
0 runts 0 giants 0 CRC 0 no buffer
0 input error 0 short frame 0 overrun 0 underrun 0 ignored
0 watchdog 0 bad etype drop 0 bad proto drop 0 if down drop
0 input with dribble 0 input discard
0 Rx pause
TX
454301132 unicast packets 734 multicast packets 72 broadcast packets
454301938 output packets 32246366102 bytes
0 jumbo packets
478920 output error 0 collision 0 deferred 0 late collision
0 lost carrier 0 no carrier 0 babble 0 output discard
0 Tx pause
Sie können sehen, dass Ethernet1/2 von Switch-1 einen Leistungsindikator ungleich null aufweist. Dies deutet darauf hin, dass die Verbindung zwischen Ethernet1/2 von Switch-1 und Ethernet1/2 von Switch-2 nicht beschädigt ist. Stattdessen ist Switch-1 ein Cut-Through-Switch, der beschädigten Datenverkehr weiterleitet, den er an einer anderen Schnittstelle empfängt. Wie bereits mit Switch-2 gezeigt, können Sie denshow interface counters errors non-zeroBefehl verwenden, um festzustellen, ob eine der Schnittstellen von Switch-1 einen Eingabefehlerzähler ungleich null aufweist.
Switch-1# show interface counters errors non-zero <snip> -------------------------------------------------------------------------------- Port Align-Err FCS-Err Xmit-Err Rcv-Err UnderSize OutDiscards -------------------------------------------------------------------------------- Eth1/1 0 478920 0 478920 0 0 Eth1/2 0 0 478920 0 0 0 -------------------------------------------------------------------------------- Port Single-Col Multi-Col Late-Col Exces-Col Carri-Sen Runts -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port Giants SQETest-Err Deferred-Tx IntMacTx-Er IntMacRx-Er Symbol-Err -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Port InDiscards --------------------------------------------------------------------------------
Wie Sie sehen, hat Ethernet1/1 von Switch-1 einen Eingabefehlerzähler ungleich null. Dies deutet darauf hin, dass Switch-1 beschädigten Datenverkehr über diese Schnittstelle empfängt. Sie wissen, dass diese Schnittstelle mit der eth0 NIC von Host-1 verbunden ist. Sie können die eth0 NIC-Schnittstellenstatistiken von Host-1 überprüfen, um zu bestätigen, ob Host-1 beschädigte Frames von dieser Schnittstelle sendet.
Host-1$ ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:50:56:84:8f:6d brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
73146816142 423112898 0 0 0 437368817
TX: bytes packets errors dropped carrier collsns
3312398924 37942624 0 0 0 0
altname enp11s0
Die eth0 NIC-Statistik von Host-1 legt nahe, dass der Host keinen beschädigten Datenverkehr überträgt. Dies deutet darauf hin, dass die Verbindung zwischen eth0 von Host-1 und Ethernet1/1 von Switch-1 beschädigt ist und die Ursache für die Beschädigung des Datenverkehrs ist. Sie müssen diesen Link beheben, um die fehlerhafte Komponente zu identifizieren, die die Beschädigung verursacht, und sie ersetzen.
Ursachen von CRC-Fehlern
Die häufigste Ursache für CRC-Fehler ist eine beschädigte oder fehlerhaft funktionierende Komponente einer physischen Verbindung zwischen zwei Geräten. Beispiele:
- Defektes oder beschädigtes physisches Medium (Kupfer oder Glasfaser) oder Direct Attach-Kabel (DACs).
- Ausgefallene oder beschädigte Transceiver/optische Verbindungen
- Fehlerhafte oder beschädigte Anschlüsse des Patchpanels.
- Fehlerhafte Hardware für Netzwerkgeräte (hierzu gehören bestimmte Ports, Line Card Application-Specific Integrated Circuits [ASICs], Media Access Controls [MACs], Fabric-Module usw.).
- Fehlerhaft funktionierende Netzwerkschnittstellenkarte, die in einen Host eingesetzt ist.
Es ist auch möglich, dass ein oder mehrere falsch konfigurierte Geräte versehentlich CRC-Fehler in einem Netzwerk verursachen. Ein Beispiel hierfür ist eine MTU-Konfigurationsabweichung (Maximum Transmission Unit) zwischen zwei oder mehr Geräten im Netzwerk, die dazu führt, dass große Pakete nicht korrekt gekürzt werden. Wenn Sie dieses Konfigurationsproblem identifizieren und beheben, können CRC-Fehler auch innerhalb des Netzwerks korrigiert werden.
CRC-Fehler beheben
Sie können die jeweilige fehlerhafte Komponente durch einen Eliminationsprozess identifizieren:
- Ersetzen Sie das physische Medium (Kupfer oder Glasfaser) oder DAC durch ein zweifelsfrei funktionierendes physisches Medium desselben Typs.
- Ersetzen Sie den in eine Geräteschnittstelle eingesetzten Transceiver durch einen zweifelsfrei funktionierenden Transceiver desselben Modells. Wenn die CRC-Fehler dadurch nicht behoben werden, ersetzen Sie den in die andere Geräteschnittstelle eingesetzten Transceiver durch einen zweifelsfrei funktionierenden Transceiver desselben Modells.
- Wenn Patchfelder als Teil des beschädigten Links verwendet werden, setzen Sie den Link an einen zweifelsfrei funktionierenden Anschluss auf dem Patchfeld. Alternativ können Sie das Patch-Panel als mögliche Ursache beseitigen, indem Sie die Verbindung möglichst ohne das Patch-Panel herstellen.
- Ziehen Sie den beschädigten Link an einen anderen, zweifelsfrei funktionierenden Port an jedem Gerät. Sie können mehrere verschiedene Ports testen müssen, um einen MAC-, ASIC- oder Linecard-Ausfall zu isolieren.
- Wenn das beschädigte Link einen Host betrifft, verschieben Sie den Link auf eine andere Netzwerkkarte auf dem Host. Alternativ können Sie die beschädigte Verbindung an einen zweifelsfrei funktionierenden Host anschließen, um einen Ausfall der Host-Netzwerkkarte zu isolieren.
Wenn es sich bei der fehlerhaften Komponente um ein Cisco Produkt (z. B. ein Cisco Netzwerkgerät oder Transceiver) handelt, das durch einen aktiven Supportvertrag abgedeckt ist, können Sie ein Support-Ticket beim Cisco TAC erstellen, Ihre Problemdetails einfügen und die fehlerhafte Komponente durch eine Retourengenehmigung (Return Material Authorization, RMA) ersetzen lassen.
Zugehörige Informationen
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
3.0 |
10-Nov-2021 |
Geringfügige Formatierung des Dokuments verbessern |
2.0 |
10-Nov-2021 |
Erstveröffentlichung |
1.0 |
10-Nov-2021 |
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Christopher HartCisco TAC Engineer
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)