Lastenausgleichslogik auf Cisco Meeting Server
Download-Optionen
-
ePub (144.9 KB)
In verschiedenen Apps auf iPhone, iPad, Android, Sony Reader oder Windows Phone anzeigen
Inklusive Sprache
In dem Dokumentationssatz für dieses Produkt wird die Verwendung inklusiver Sprache angestrebt. Für die Zwecke dieses Dokumentationssatzes wird Sprache als „inklusiv“ verstanden, wenn sie keine Diskriminierung aufgrund von Alter, körperlicher und/oder geistiger Behinderung, Geschlechtszugehörigkeit und -identität, ethnischer Identität, sexueller Orientierung, sozioökonomischem Status und Intersektionalität impliziert. Dennoch können in der Dokumentation stilistische Abweichungen von diesem Bemühen auftreten, wenn Text verwendet wird, der in Benutzeroberflächen der Produktsoftware fest codiert ist, auf RFP-Dokumentation basiert oder von einem genannten Drittanbieterprodukt verwendet wird. Hier erfahren Sie mehr darüber, wie Cisco inklusive Sprache verwendet.
Informationen zu dieser Übersetzung
Cisco hat dieses Dokument maschinell übersetzen und von einem menschlichen Übersetzer editieren und korrigieren lassen, um unseren Benutzern auf der ganzen Welt Support-Inhalte in ihrer eigenen Sprache zu bieten. Bitte beachten Sie, dass selbst die beste maschinelle Übersetzung nicht so genau ist wie eine von einem professionellen Übersetzer angefertigte. Cisco Systems, Inc. übernimmt keine Haftung für die Richtigkeit dieser Übersetzungen und empfiehlt, immer das englische Originaldokument (siehe bereitgestellter Link) heranzuziehen.
Inhalt
Einleitung
Dieses Dokument beschreibt die Load Balancing-Logik des Cisco Meeting Server (CMS) (ehemals Acano-Produkt), der im Whitepaper Load Balancing behandelt wird. In diesem Dokument wird dieser Prozess in einem Flussdiagramm dargestellt und der Auswahlalgorithmus im Detail beschrieben.
Voraussetzungen
Anforderungen
Cisco empfiehlt, dass Sie über Kenntnisse in folgenden Bereichen verfügen:
- Cisco Meeting Server Call Bridge-Komponente (und Clustering)
- API-Konfiguration für Cisco Meeting Server
Verwendete Komponenten
Die Informationen in diesem Dokument basieren auf Cisco Meeting Server, Version 2.4.x.
Die Informationen in diesem Dokument beziehen sich auf Geräte in einer speziell eingerichteten Testumgebung. Alle Geräte, die in diesem Dokument benutzt wurden, begannen mit einer gelöschten (Nichterfüllungs) Konfiguration. Wenn Ihr Netzwerk in Betrieb ist, stellen Sie sicher, dass Sie die möglichen Auswirkungen aller Befehle verstehen.
Was ist der Load Balancing Algorithmus des CMS?
In Version 2.1 von CMS wurde der Lastenausgleich eingeführt, um Konferenzressourcen effizient zu nutzen. Er versucht, die Anzahl der Verteilungsaufrufe zwischen den Call Bridges, die denselben Speicherplatz hosten, zu minimieren. Dieser Mechanismus basiert auf dem Replaces-Header im SIP (Session Initiation Protocol) und wird in Cisco Unified Communications Manager (CUCM) als Anrufsteuerung unterstützt. Es wird auch mit Expressway Version X8.11 (oder höher) unterstützt, in Kombination mit einer CMS Version 2.4 oder höher. CMA-Aufrufe (sowohl vom Typ Thick Client als auch vom Typ WebRTC) können ab CMS Version 2.3 mit Lastausgleich ausgeführt werden.
Hinweis: Load Balancing von Lync/Skype-Anrufen wird derzeit in keiner CMS-Version unterstützt. Daher gilt dieses Flussdiagramm nicht.
Hinweis: Die Load Balancing-Logik gilt nur für Anrufe an CMS-Standorte und daher derzeit nicht für Gateway-Anrufe (P2P-Anrufe) oder Dual-Home-Anrufe.
Der Lastenausgleichsprozess wird im Whitepaper im Abschnitt Wie Lastenausgleich die Einstellungen unter Konfigurieren von Anrufbrücken für Lastenausgleich bei eingehenden Anrufen verwendet, hervorgehoben. Es ist im Textformat dargestellt und wird hier im Flussdiagramm dargestellt (Download ).
Im Flussdiagramm werden einige Abkürzungen und Begriffe verwendet:
- CB = Call Bridge
- ExistingConferenceLoadLimit = existingConferenceLoadLimitBasisPoints * loadLimit
(der Wert von existingConferenceLoadLimitBasisPoints entspricht standardmäßig 8000, was 80% entspricht) - NewConferenceLoadLimit = newConferenceLoadLimitBasisPoints * loadLimit
(standardmäßig entspricht newConferenceLoadLimitBasisPoints 5000, was 50 % entspricht)
Wenn auf MediaProcessingLoad verwiesen wird, wird dies in Bezug auf die jeweilige Anrufbrücke angezeigt, an der der Anruf gelandet ist. Dieser Lastwert kann mit einem API GET on /system/load in Echtzeit überprüft werden und gibt eine Darstellung der tatsächlichen Last, die von dieser Call Bridge zu diesem Zeitpunkt verarbeitet wird.
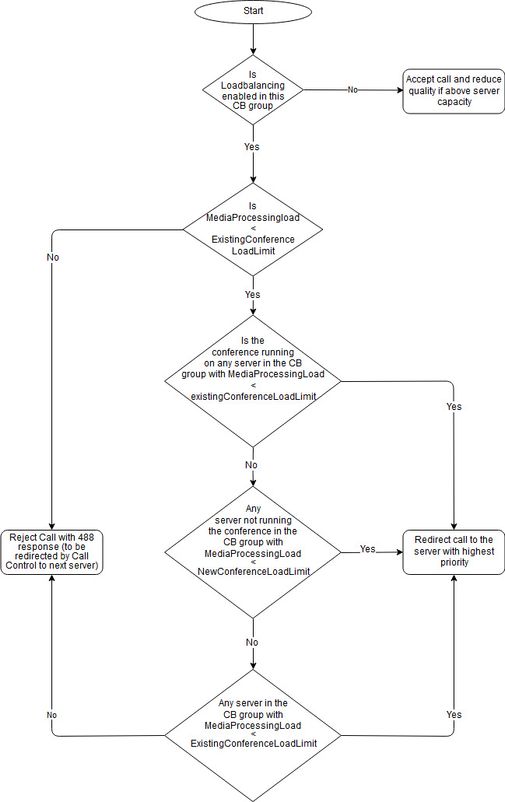
Wenn Sie den Anruf in das Feld ganz unten rechts stellen, wird er an den Server mit der höchsten Priorität umgeleitet. Dies kann der Call Bridge-Server selbst oder ein anderer Server innerhalb der Call Bridge-Gruppe sein, auf dem der Anruf gelandet ist. Falls keine Entscheidung getroffen wird, die auf der Last basiert und ob der Speicherplatz bereits auf einer Call Bridge aktiv ist, gibt es eine Verknüpfung mit mehreren Call Bridges. In diesem Fall wird die endgültige Entscheidung auf der Grundlage der Standardeinstellung für die Anrufbrücke getroffen, die jedem Space zugewiesen wird. Diese Call Bridge-Präferenz wird beim Erstellen des Speicherplatzes automatisch zugewiesen und kann nicht konfiguriert werden, da sie auf den Hash-Werten mehrerer Attribute basiert. Dies führt zu einer gleichmäßigen (zufälligen) Verteilung für verschiedene Räume auf alle Call Bridges.
Um die Call Bridge-Voreinstellungen für einen bestimmten Bereich anzuzeigen, müssen Sie diese im CMS-Ereignisprotokoll überprüfen, wie in diesen Beispielen gezeigt.
Beispiele für den Load Balancing-Algorithmus
Dieser Abschnitt enthält Beispiele für mögliche Szenarien und zeigt, wie das Ereignisprotokoll des CMS, in dem der Anruf gelandet ist, den Lastenausgleichsprozess wie im Flussdiagramm behandelt anzeigt.
Für diese Beispiele wurde eine Übungseinheit mit einer aus drei Call Bridges bestehenden Call Bridge-Gruppe verwendet. Die Konfigurationen existingConferenceLoadLimitBasisPoints und newConferenceLoadLimitBasisPoints wurden auf ihre Standardwerte festgelegt, die 80 % bzw. 50 % des loadLimit-Werts entsprechen.
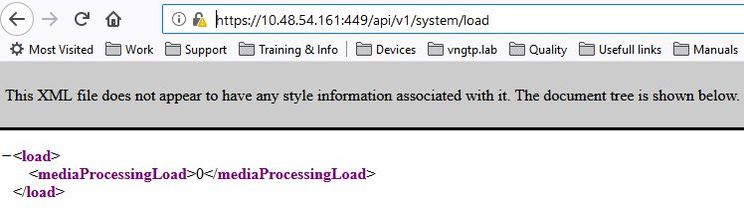
Um die aktuelle MediaProcessingLoad auf einer bestimmten Anrufbrücke zu überprüfen, können Sie zu https://<ip-or-fqdn-of-callbridge>:<webadmin-port>/api/v1/system/load navigieren und sich mit einem API- oder Admin-Konto anmelden, wie auf dem Bild angezeigt.
Beispiel 1: Keine Last auf einer Anrufbrücke
In diesem Beispiel sind an keiner der Call Bridges Anrufe aktiv. Die MediaProcessingLoad aller Server entspricht somit Null.
Wenn Sie einen Anruf an eine der Call Bridges (Cluster1 hier) tätigen (wobei Load Balancing sowohl auf dem CMS als auch auf den Anrufsteuerungsgeräten aktiviert ist), können Sie das Ereignisprotokoll auf der Call Bridge sehen, in dem der Anruf gelandet ist:
2018-12-29 10:51:29.490 Info call 75: incoming SIP call from "sip:1060@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 10:51:29.565 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 10:51:29.712 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 10:51:29.717 Info replacing call 'f8eeea46e0f0790a@10.10.50.13' to conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 on server 'cluster3' 2018-12-29 10:51:29.876 Info call 75: ending; remote SIP cancel (remote cancel) - not connected after 0:00
in dem Sie die Ersetzungsabfragelinien für jede der Anrufbrücken in Ihrer Anrufbrücken-Gruppe sehen, die uns den Lastenausgleichsalgorithmus zeigen, der in drei Abschnitte aufgeteilt ist:
- priority (Priorität): die Call Bridge-Präferenz dieses Space
- Load-Level - Der Load-Level dieser Call Bridge zu diesem Zeitpunkt.
- Konferenz wird ausgeführt - Boolesch, ob der Raum auf dieser Anrufbrücke aktiv ist
Da zu diesem Zeitpunkt keine Anrufe in das System getätigt wurden, wird keines der Systeme (alle 0) belastet, und die Konferenz wird nirgends (alle 0) ausgeführt. In dieser Hinsicht wird die endgültige Entscheidung auf der Grundlage der Call Bridge-Präferenz des Raums getroffen. Eine niedrigere Priorität wird bevorzugt, und daher wird der Anruf hier durch die Anrufbrücke mit dem Namen Cluster3 ersetzt, die durch die ersetzende Anrufleitung angezeigt wird.
Auf Call Bridge-Cluster3 sehen Sie die Ereignisprotokollzeilen, die angeben, dass ein Anruf ersetzt wird (sowie die Anrufbrücke, von der er stammt (Cluster1 hier), und die gleiche Konferenz-ID und Anruf-ID):
2018-12-29 10:51:29.784 Info replacing call 'f8eeea46e0f0790a@10.10.50.13' from server 'cluster1' into conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 2018-12-29 10:51:29.787 Info call 193: outgoing SIP call to "1060@steven.lab" from space "Steven Janssens's space" 2018-12-29 10:51:29.792 Info call 193: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 10:51:29.909 Info call 193: compensating for far end not matching payload types 2018-12-29 10:51:29.911 Info participant "1060@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Falls der Anruf bereits auf der Anrufbrücke mit dem niedrigsten Prioritätswert gelandet ist (Cluster3 hier für diesen Bereich), können Sie im Ereignisprotokoll immer noch die gleichen Ersetzungsabfragelinien sehen, aber jetzt wird angezeigt, dass der lokale Server verwendet wird und es keine Ersetzungsanrufleitung gibt:
2018-12-29 11:05:25.202 Info call 194: incoming SIP call from "sip:1060@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 11:05:25.233 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 11:05:25.376 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 11:05:25.378 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 11:05:25.378 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster3' (priority: 0, load level: 0, conference is running: 0) 2018-12-29 11:05:25.380 Info call 194: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 11:05:25.404 Info participant "1060@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Beispiel 2: Bereits Teilnehmer in der Call Bridge-Gruppe
In diesem Beispiel ist der Space bereits in der Call Bridge-Gruppe als Endpunkt 1060@steven.lab aktiv, der in den Space aufgerufen wird, wie in Beispiel 1 gezeigt.
In diesem Fall gibt es zwei Situationen:
1. Die Call Bridge, die diesen Space hostet, hat eine Last, die unter dem vorhandenen Konferenzschwellenwert liegt, und kann den Anruf daher annehmen.
2. Die Call Bridge, die diesen Space hostet, hat eine höhere Last als der vorhandene Konferenzschwellenwert. Daher versucht CMS, den Anruf durch eine andere Call Bridge zu ersetzen.
Szenario 1. Aktiver Raum und Last unter dem vorhandenen Konferenzschwellenwert (80 %)
Falls der Anruf auf einer Anrufbrücke gelandet ist, auf der der Speicherplatz noch nicht aktiv war, zeigt das Ereignisprotokoll jetzt, dass der Speicherplatz auf der Anrufbrücke mit dem Namen cluster3 aktiv ist. Da der Speicherplatz dort aktiv ist und die Last auf diesem Server unter dem vorhandenen Schwellenwert liegt (Laststufe: 0), wird der Anruf ersetzt.
2018-12-29 11:48:17.419 Info call 82: incoming SIP call from "sip:800999@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 11:48:17.477 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 0, conference is running: 1) 2018-12-29 11:48:17.607 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster3' (priority: 0, load level: 0, conference is running: 1) 2018-12-29 11:48:17.607 Info replacing call '4c28197eaebba178@10.10.2.250' to conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93 on server 'cluster3'
Die ausgeführte Konferenz nimmt zuerst die Priorität vor. Wenn also mehrere Kandidaten mit einem Lastpegel unter dem vorhandenen Konferenzschwellenwert vorhanden wären, würde sie entsprechend dem Prioritätswert auf die Call Bridge-Präferenz heruntergestuft. Das ist hier jedoch nicht der Fall.
Szenario 2. Aktiver Raum und Last höher als der vorhandene Konferenzschwellenwert (80 %)
In diesem Fall wird der Anruf nicht durch diese Anrufbrücke ersetzt, sondern es wird nach einer anderen Anrufbrücke innerhalb der Gruppe gesucht, für die noch einige Ressourcen verfügbar sind. Zunächst wird überprüft, ob Call Bridges mit einer Last von weniger als 50 % vorhanden sind (neuer Konferenzschwellenwert), und diese Bridges werden zuerst geladen. Wenn unter diesem Schwellenwert keine verfügbar sind, wird geprüft, ob unter dem Schwellenwert von 80 % noch eine Verfügbarkeit besteht (vorhandener Schwellenwert für Konferenzen).
Wenn die Last für Call Bridge-Cluster3 nach den Aufrufen der Beispiele 1 und 2 (Szenario 1) überprüft wird, wird eine Last von 2000 angezeigt.
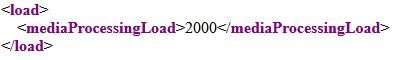
Angenommen, der loadLimit für diesen Call Bridge-Cluster3 wurde auf 2250 festgelegt (nur als Beispiel), dann überschreitet diese Call Bridge den vorhandenen Konferenzschwellenwert, da dieser als 0,80 * 2250 = 1800 berechnet wird.
In diesem Szenario müssen noch zwei Fälle unterschieden werden.
Fall 1: Mehrere Server in der Gruppe, deren Last immer noch unter dem neuen Konferenzschwellenwert liegt (50 %)
Auf den beiden anderen Servern der Gruppe werden noch keine Anrufe verarbeitet, sodass die Last immer noch bei 0 liegt und sie beide den Anruf verarbeiten könnten. Die Endentscheidung wird somit basierend auf der Call Bridge-Präferenz für diesen Bereich getroffen. Da Cluster 3 der Anrufbrücke bereits voll ist, wählen die Systeme die niedrigste Priorität aus Cluster 1 und Cluster 2 aus, in diesem Fall Cluster 1.
2018-12-29 12:11:03.211 Info call 86: incoming encrypted SIP audio call from "sip:2001@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 12:11:03.263 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 12:11:03.405 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 0, conference is running: 0) 2018-12-29 12:11:03.412 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:11:03.412 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster1' (priority: 1, load level: 0, conference is running: 0) 2018-12-29 12:11:03.415 Info call 86: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 12:11:03.434 Info participant "2001@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Beachten Sie, dass der Lastpegel "2" auf der Cluster3-Anrufbrücke anzeigt, dass der vorhandene Konferenzschwellenwert überschritten wurde. Obwohl der Raum dort aktiv war, wird für den Anruf daher kein Load Balancing auf diesen Server durchgeführt. Stattdessen wird die niedrigste Speicherplatzpriorität der anderen Anrufbrücken mit einem Load-Level betrachtet: 0 (d. h. eine Nutzung, die unter 50 % liegt), in diesem Fall Cluster1.
Fall 2: Nur ein Server in einer Gruppe mit einer Last, die unter dem neuen Konferenzschwellenwert (50 %) oder dem vorhandenen Konferenzschwellenwert (80 %) liegt
Nach dem letzten Anruf (und Anrufen von Cluster2 an andere Standorte) wurden die beschriebenen Lasten auf den Anrufbrücken erkannt:
- Cluster 1 - 1200
- Cluster 2 - 400
- Cluster 3 - 4000
Angenommen, der loadLimit für Cluster1-Anrufbrücke beträgt 1300, dann hat diese Anrufbrücke den neuen Konferenzschwellenwert überschritten, der als 0,50 x 1300 = 650 berechnet wird, sowie den vorhandenen Konferenzschwellenwert von 0,80 x 1300 = 1040.
Falls ein neuer WebRTC-Anruf jetzt für den gleichen Raum auf Call Bridge Cluster3 eingeht, ist der Raum sowohl auf Cluster1 als auch auf Cluster3 aktiv, aber beide liegen über dem bestehenden Konferenzschwellenwert und suchen daher nach einem anderen Server unter dem neuen Konferenzschwellenwert (50 %) oder dem vorhandenen Konferenzschwellenwert (80 %). In diesem Fall läge nur Cluster2 noch unter dem bestehenden Konferenzschwellenwert, dieser liegt jedoch bereits über dem neuen Konferenzschwellenwert, da ein anderer Anruf an einen anderen auf Cluster2-Anrufbrücke verarbeiteten Raum eingeht.
2018-12-29 12:45:33.162 Info instantiating user "guest1685904798@cluster.steven.lab" 2018-12-29 12:45:33.162 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster1' (priority: 1, load level: 2, conference is running: 1) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:45:33.299 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using remote server 'cluster2' (priority: 2, load level: 1, conference is running: 0)
Cluster2 wurde mit einem loadLimit-Wert von 600 eingerichtet. Mit 400 als aktueller Last vor dem Eingehen des neuen Anrufs liegt er über dem neuen Konferenzschwellenwert von 0,5 * 600 = 300, aber immer noch unter dem bestehenden Konferenzlimit von 0,8 * 600 = 480. Dies wird in der Ersetzungsabfrage als Laststufe angezeigt: 1 (anstelle von 2, wenn die Anrufbrücke den Schwellenwert von 80 % überschreitet).
Beispiel 3: Anrufanlandung auf der Anrufbrücke über den bestehenden Konferenzschwellenwert
In diesem Fall findet der Lastenausgleichsalgorithmus nicht statt, da es besser wäre, eine 488-Antwort zurück an das Anrufsteuergerät zu senden, das dann entscheiden kann, den Anruf an eine andere Anrufbrücke innerhalb der Gruppe weiterzuleiten (die unter der 80 %-Grenze liegen kann) oder ihn sogar an eine andere Anrufbrücken-Gruppe weiterzuleiten, wenn die aktuelle Gruppe nicht über ausreichende Ressourcen verfügt (als Fallback-Option).
Das Ereignisprotokoll zeigt diesen Teil nicht explizit im Detail an, da es lediglich berichtet, dass er die Kapazität überschritten hat:
2018-12-29 12:49:13.352 Info call 88: incoming encrypted SIP call from "sip:2020@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab" 2018-12-29 12:49:13.399 Info call 88: ending; local teardown, system participant limit reached - not connected after 0:00
Wenn der Anruf an eine andere Anrufbrücke gesendet wird, die die Last verarbeiten kann (z. B. Cluster2), wird derselbe Lastverteilungsalgorithmus angezeigt:
2018-12-29 12:49:13.434 Info call 624: incoming encrypted SIP call from "sip:2020@steven.lab" to local URI "sip:stejanss.space@cluster.steven.lab"
2018-12-29 12:49:13.475 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:49:13.614 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: response from 'cluster3' (priority: 0, load level: 2, conference is running: 1) 2018-12-29 12:49:13.614 Info replace query for conference 4d2542b2-8e72-45f5-a66c-f8a95f355f93: using local server 'cluster2' (priority: 2, load level: 1, conference is running: 0) 2018-12-29 12:49:13.618 Info call 624: setting up UDT RTP session for DTLS (combined media and control) 2018-12-29 12:49:13.621 Info call 624: starting DTLS UDT media negotiation (as initiator) 2018-12-29 12:49:13.640 Info participant "2020@steven.lab" joined space bc218bfb-3bda-44f6-89a7-80d8dd616a80 (Steven Janssens's space)
Hinweis: Bei Gateway-Anrufen gibt das CMS stattdessen eine 486 SIP-Fehlermeldung zurück. Standardmäßig stoppt CUCM die Weiterleitung gemäß dem Service-Parameter "Stopp Routing on User Busy Flag" (Weiterleitung bei Besetztzeichen beenden). Sie können diese Einstellung ändern, um Fallback für Gateway-Anrufe an andere Callbridges zuzulassen.
Revisionsverlauf
| Überarbeitung | Veröffentlichungsdatum | Kommentare |
|---|---|---|
1.0 |
30-Apr-2019 |
Erstveröffentlichung |
Beiträge von Cisco Ingenieuren
- Steven JanssensCisco TAC Engineer
- Nart OmatCisco TAC Engineer
 Feedback
FeedbackCisco kontaktieren
- Eine Supportanfrage öffnen

- (Erfordert einen Cisco Servicevertrag)